AI/Machine Learning
[ML] K-평균(K-Means)이란?
운호(Noah)
2020. 11. 2. 15:48
비지도 학습
- 비지도 학습이란, 입력 데이터에 대한 출력 값(정답) 없이,
- 오직 입력 데이터만으로 학습을 진행한 뒤,
- 데이터로부터 유의미한 정보를 추출하는 머신러닝 기법입니다.
주요 기술
군집화(Clustering)
- 유사한 데이터들을 그룹화하는 작업
비정상 탐지(Anomaly detection)
- 예상치 못한 이벤트 또는 결과를 식별하는 작업
차원 축소(Dimension reduction)
- 고려해야하는 Feature 의 개수를 줄이는 작업
- 상관관계가 있는 여러 Feature 를 하나로 합치는 작업
K-Means Clustering
- K-Means Clustering 은 Clustering 기법 중 하나이며, K 는 데이터를 몇 개의 클러스터로 분할할지를 의미합니다.
- 알고리즘 순서
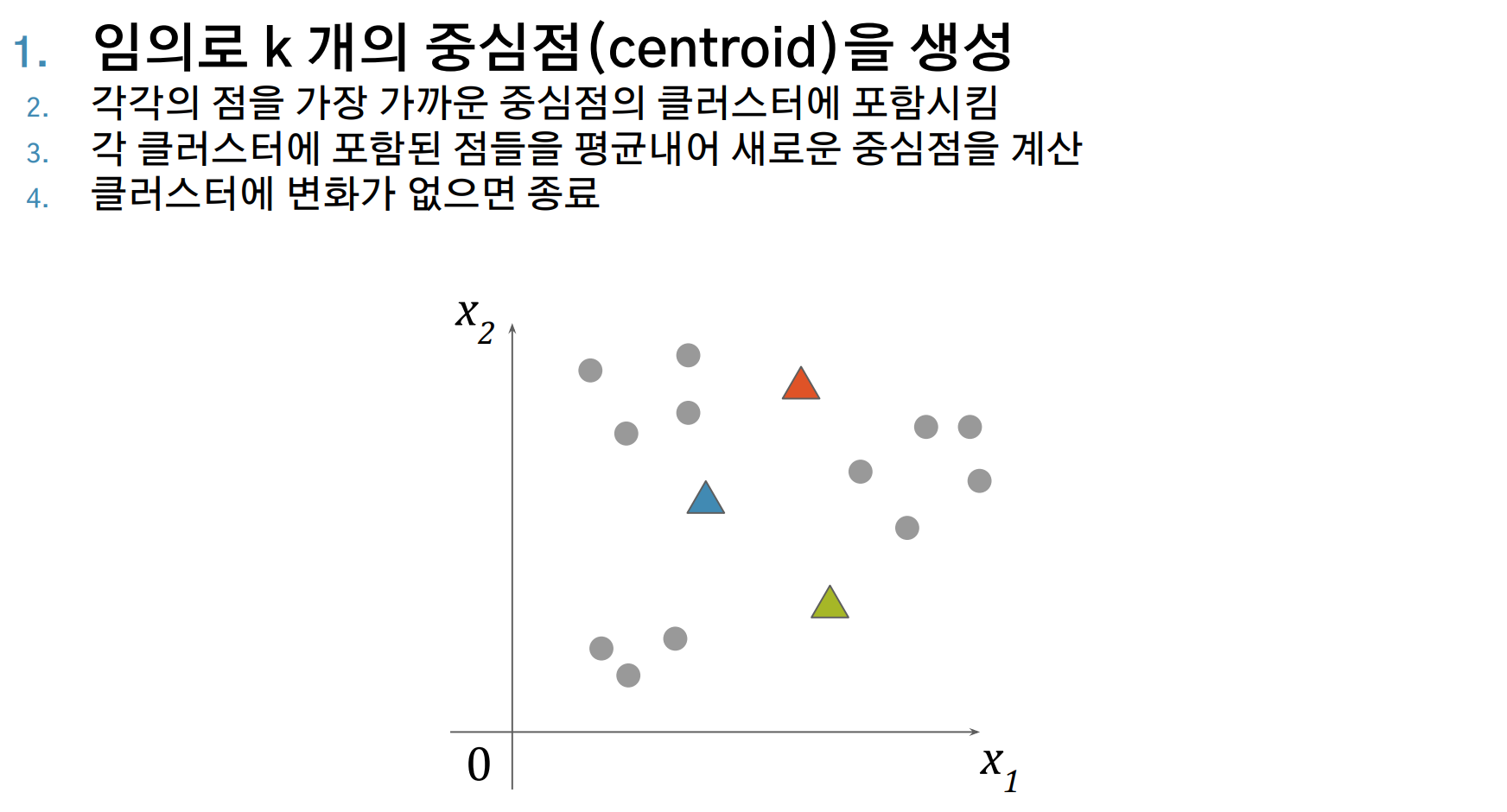
- 임의로 k 개의 중심점(centroid)을 생성합니다.
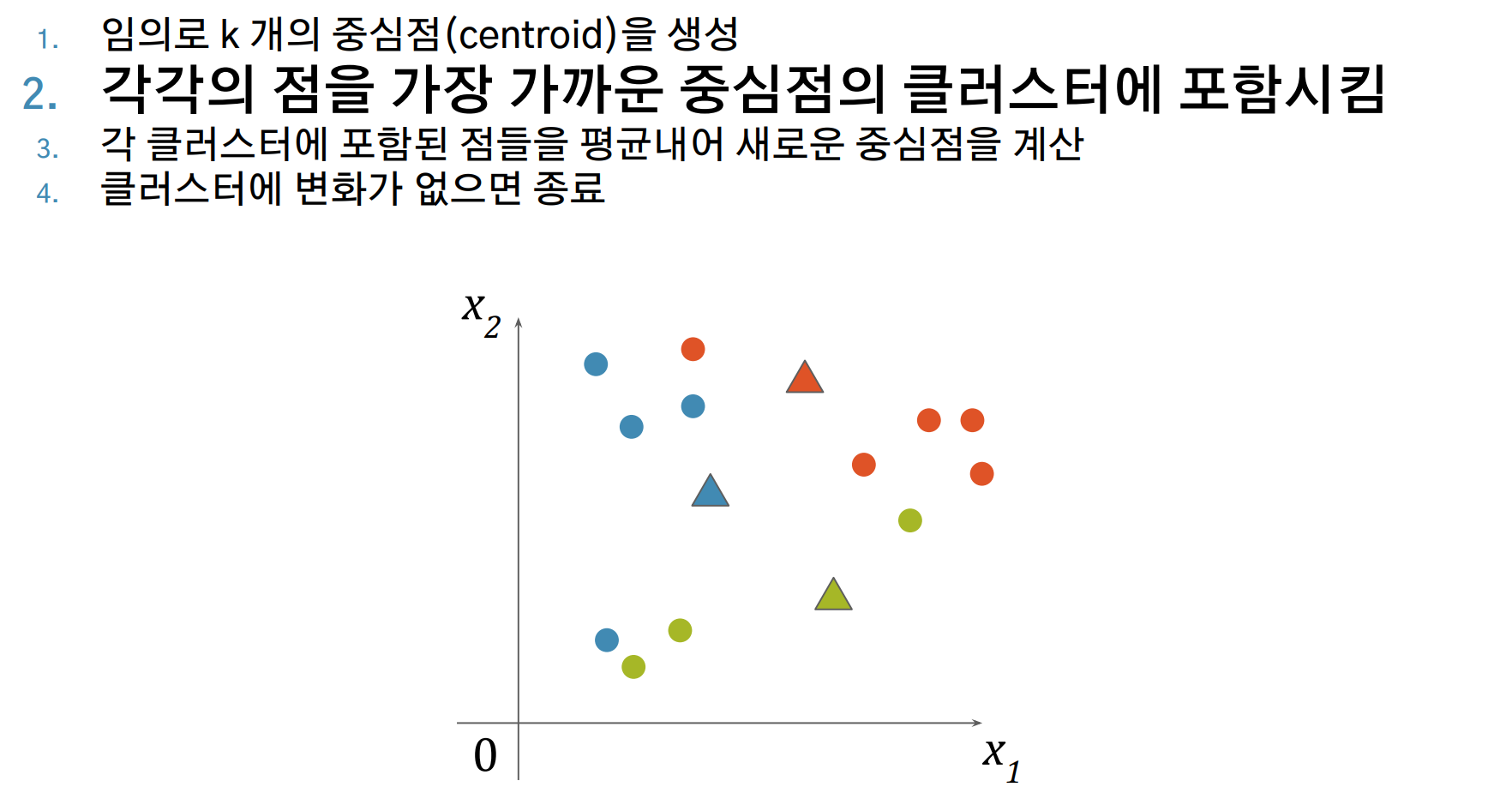
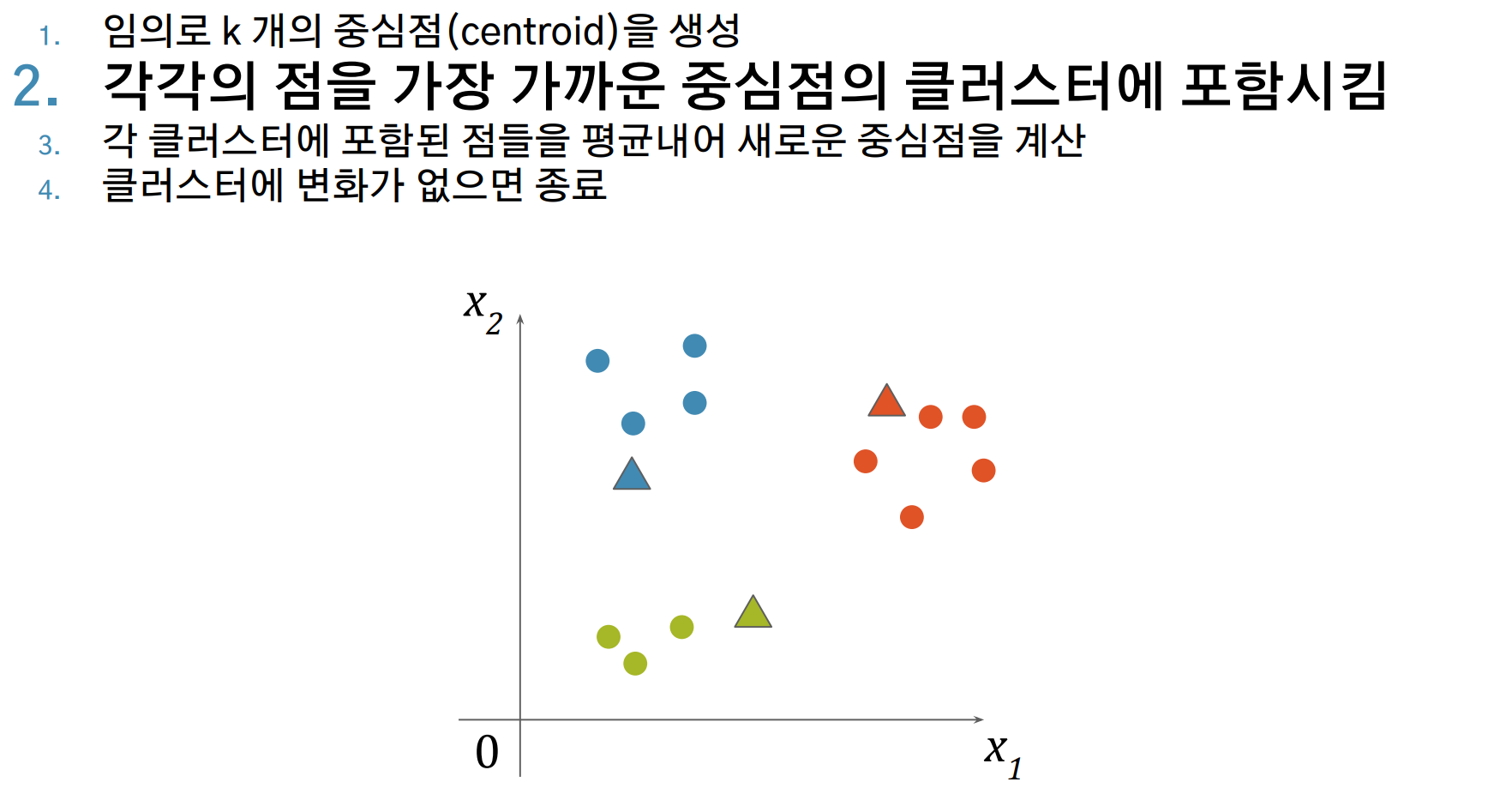
- 각각의 데이터를, 가장 가까운 중심점의 클러스터에 포함시킵니다.
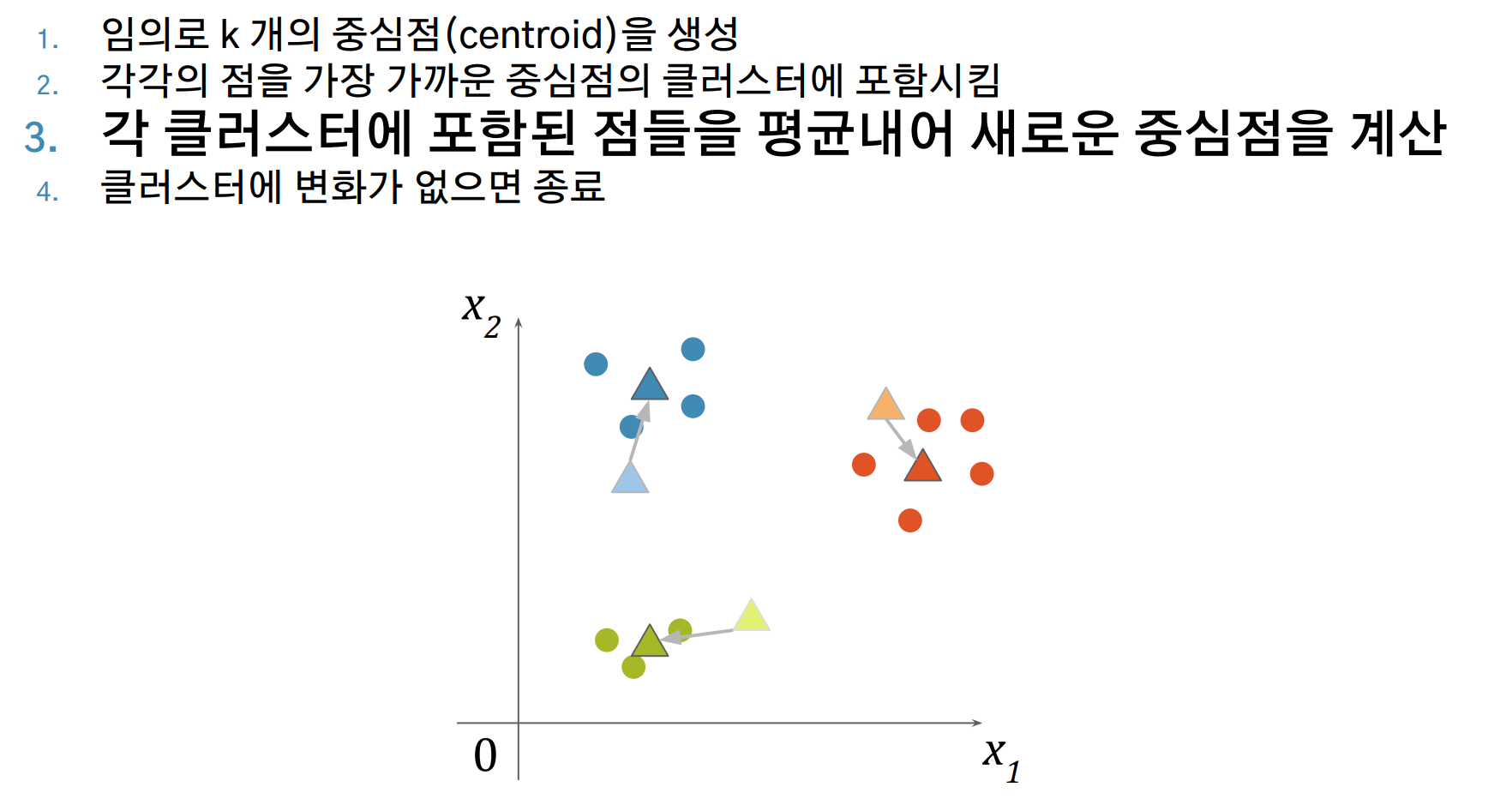
- 각 클러스터에 포함된 점들을 평균내어 새로운 중심점을 계산합니다.
- 2번 ~ 3번을 반복하며, 클러스터에 변화가 없으면 종료합니다.
K-Means Clustering 알고리즘 시각화


중심점 초기화 방법
- K-Means 알고리즘은 적절하지 않은 시작 중심점 위치로 인해 Local Optimum 에 빠질 수 있습니다
- 또한, 중심점 초기화 방법에 따라 결과가 달라질 수 있으며, 중심점 초기화 방법은 아래와 같은 방법들이 있습니다.
- 1) 임의의 벡터로 중심점 초기화
- 여러번 반복하여 가장 좋은 결과 선택
- 2) Forgy
- 데이터 점 들 중 임의로 선택
- 3) 직접 중심점 지정하기
- 데이터를 얼추 알고 있을 때 사용
- 4) K-Means++
- 멀리 떨어진 점들을 초기 중심점으로 사용
- 1) 임의의 벡터로 중심점 초기화
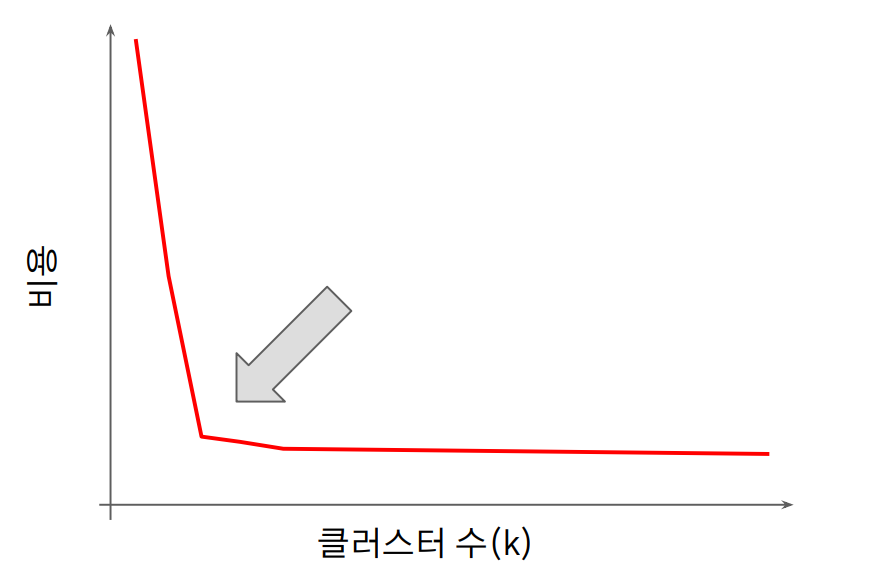
K 값 (클러스터 개수) 선택하기
K 값 (클러스터 개수)을 1 부터 증가시켜가며, K 값에 따른 비용을 분석한 뒤,
비용의 감소가 급격히 줄어드는 지점으로 K 를 선택합니다.
비용 분석에 사용되는 비용함수는 아래와 같습니다.
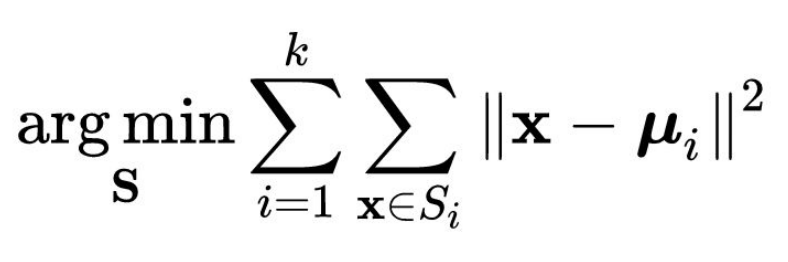
- x : 데이터
- μi : i 번째 클러스터의 중심 (데이터 평균)
- k : 클러스터 수
- S : 데이터 집합