
우노
[Spark] Matrix의 Row를 전체 Vertex 개수로 두고 (LRxLC),(LCxLC) 형태 Matrix 생성하기 본문
Data/Spark
[Spark] Matrix의 Row를 전체 Vertex 개수로 두고 (LRxLC),(LCxLC) 형태 Matrix 생성하기
운호(Noah) 2020. 10. 14. 15:27Matrix의 Row를 전체 Vertex 개수로 두고 (LRxLC),(LCxLC) 형태 Matrix 생성하기
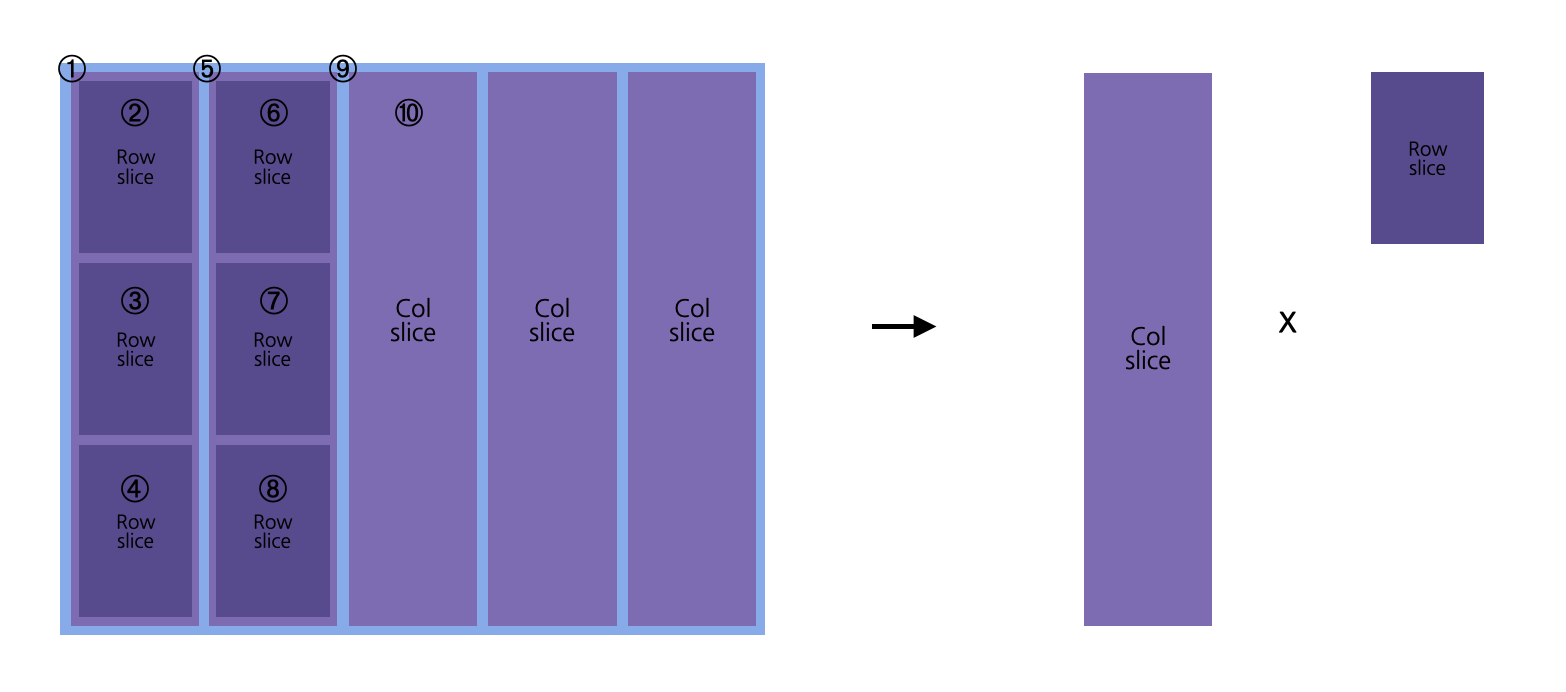
위 그림의 1~10 과 같은 순서로 중첩루프를 돌며 (LRxLC),(LCxLC) Matrix를 생성합니다.
자세한 코드 설명
- 1) Matrix 데이터 입력
- 2) 입력 데이터의 row, col 크기 입력
- 3) col slice 단위 설정
- 4) 최대 col slice 크기 설정 (slice의 nnz가 10^9 를 넘으면 안되므로)
- 5) LR을 전체 vertex 개수로 두고 col slice 생성
- 각 col slice 저장 (nnz, density 기입)
- 각 col slice에서 LCxLC 크기의 row slice 생성
- 각 row slice 저장 (nnz, density 기입)
- row slice는 최대 10개까지만 생성
- 6) 해당 col slice 단위에 대해 모든 청크들을 생성 했다면 slice 단위를 증가시킨 후 5)부터 다시 진행
- 7) col slice는 단위당 최대 10개까지만 생성하며, col slice 단위가 최대 col slice 단위가 될 때 까지 진행
예제 코드
import scala.math.BigDecimal import scala.util.control._ // Breaks 객체 생성 var loop = new Breaks val input = sc.textFile("s3://matlab-square-matrix/M_1024_1024_0.001.txt") // 입력 데이터 row, col 크기 val input_row: Long = 1024 val input_col: Long = 1024 // col slice 단위 var col_unit = 300 // col slice 증가 단위 var col_unit_add = 100 // 최대 col slice 단위 val max_col_unit = 700 // 단위 당 slice 할 max col 개수 val max_col_slice = 10 // 단위 당 slice 할 max row 개수 val max_row_slice = 10 // col slice 단위가 최대 단위를 넘지 않도록 while (col_unit <= max_col_unit){ // col slice의 시작,끝 index var col_unit_start_idx = 1 var col_unit_end_idx = col_unit // 뽑은 col slice 개수 var col_slice_count = 0 loop.breakable{ // 입력 데이터의 col 크기 안에서만 col slice가 가능하도록 while (col_unit_end_idx <= input_col){ // col slice 개수 증가 col_slice_count = col_slice_count + 1 // 뽑은 col slice 개수가 max_col_slice 개수를 초과하면 중단 if (col_slice_count > max_col_slice){ loop.break } // col slice 생성 var col_slice = input.map{x=>x.split(" ")}.map{x => (x(0).toInt, x(1).toInt, x(2).toDouble)}.filter{x=> x._2 >= col_unit_start_idx && x._2 <= col_unit_end_idx} // col slice의 nnz val col_slice_nnz = col_slice.count // col slice의 density를 소수점 6자리로 반올림 val col_slice_density = BigDecimal(col_slice_nnz.toDouble / (input_row * col_unit).toDouble).setScale(6, BigDecimal.RoundingMode.HALF_UP) // col slice의 col idx 재정렬 col_slice = col_slice.map{x => (x._1, x._2 - col_unit_start_idx, x._3)} val col_chunk = col_slice.map{x=>x._1 + " " + x._2 + " " + x._3} // Property가 기입된 Left slice 저장, s3에 동일한 파일이 있을 경우엔 저장하지 않는다. try{ col_chunk.coalesce(1).saveAsTextFile("s3://non-square-matrix/M_"+input_row+"_"+col_unit+"_"+col_slice_nnz+"_"+col_slice_density+".txt") println("s3://non-square-matrix/M_"+input_row+"_"+col_unit+"_"+col_slice_nnz+"_"+col_slice_density+".txt") }catch{ case x: org.apache.hadoop.mapred.FileAlreadyExistsException => { println("s3://non-square-matrix/M_"+input_row+"_"+col_unit+"_"+col_slice_nnz+"_"+col_slice_density+".txt"+" Already Exists in S3") } } // col slice의 row, col 크기 val col_slice_row = input_row val col_slice_col = col_unit // row slice 단위 val row_unit = col_unit // row slice의 시작,끝 index var row_unit_start_idx = 1 var row_unit_end_idx = row_unit // 뽑은 row slice 개수 var row_slice_count = 0 loop.breakable{ // col slice의 row 크기 안에서만 row slice가 가능하도록 while (row_unit_end_idx <= col_slice_row){ // row slice 개수 증가 row_slice_count = row_slice_count + 1 // 뽑은 row slice 개수가 max_row_slice 개수를 초과하면 중단 if (row_slice_count > max_row_slice){ loop.break } // row slice 생성 val row_slice = col_slice.filter{x=> x._1 >= row_unit_start_idx && x._1 <= row_unit_end_idx} // row slice의 nnz val row_slice_nnz = row_slice.count // row slice의 density를 소수점 6자리로 반올림 val row_slice_density = BigDecimal(row_slice_nnz.toDouble / (row_unit * col_slice_col).toDouble).setScale(6, BigDecimal.RoundingMode.HALF_UP) // row slice의 row idx 재정렬 val row_chunk = row_slice.map{x => (x._1 - row_unit_start_idx, x._2, x._3)}.map{x=>x._1 + " " + x._2 + " " + x._3} // Property가 기입된 Right slice 저장, s3에 동일한 파일이 있을 경우엔 저장하지 않는다. try{ row_chunk.coalesce(1).saveAsTextFile("s3://non-square-matrix/M_"+row_unit+"_"+col_slice_col+"_"+row_slice_nnz+"_"+row_slice_density+".txt") println("s3://non-square-matrix/M_"+row_unit+"_"+col_slice_col+"_"+row_slice_nnz+"_"+row_slice_density+".txt") }catch{ case x: org.apache.hadoop.mapred.FileAlreadyExistsException => { println("s3://non-square-matrix/M_"+row_unit+"_"+col_slice_col+"_"+row_slice_nnz+"_"+row_slice_density+".txt"+" Already Exists in S3") } } row_unit_start_idx = row_unit_start_idx + row_unit row_unit_end_idx = row_unit_end_idx + row_unit } } col_unit_start_idx = col_unit_start_idx + col_unit col_unit_end_idx = col_unit_end_idx + col_unit } } // col slice 단위 증가 col_unit = col_unit + col_unit_add }결과
입력 Matrix의 사이즈는 1024*1024
col slice 단위는 300
col slice 증가 단위는 100
max col slice 단위는 700
s3://non-square-matrix/M_1024_300_268_0.000872.txt s3://non-square-matrix/M_300_300_61_0.000678.txt s3://non-square-matrix/M_300_300_65_0.000722.txt s3://non-square-matrix/M_300_300_95_0.001056.txt s3://non-square-matrix/M_1024_300_272_0.000885.txt s3://non-square-matrix/M_300_300_89_0.000989.txt s3://non-square-matrix/M_300_300_55_0.000611.txt s3://non-square-matrix/M_300_300_93_0.001033.txt s3://non-square-matrix/M_1024_300_342_0.001113.txt s3://non-square-matrix/M_300_300_97_0.001078.txt s3://non-square-matrix/M_300_300_76_0.000844.txt s3://non-square-matrix/M_300_300_123_0.001367.txt s3://non-square-matrix/M_1024_400_343_0.000837.txt s3://non-square-matrix/M_400_400_109_0.000681.txt s3://non-square-matrix/M_400_400_154_0.000963.txt s3://non-square-matrix/M_1024_400_464_0.001133.txt s3://non-square-matrix/M_400_400_172_0.001075.txt s3://non-square-matrix/M_400_400_201_0.001256.txt s3://non-square-matrix/M_1024_500_422_0.000824.txt s3://non-square-matrix/M_500_500_173_0.000692.txt s3://non-square-matrix/M_500_500_230_0.000920.txt s3://non-square-matrix/M_1024_500_546_0.001066.txt s3://non-square-matrix/M_500_500_210_0.000840.txt s3://non-square-matrix/M_500_500_311_0.001244.txt s3://non-square-matrix/M_1024_600_540_0.000879.txt s3://non-square-matrix/M_600_600_270_0.000750.txt s3://non-square-matrix/M_1024_700_678_0.000946.txt s3://non-square-matrix/M_700_700_430_0.000878.txt
'Data > Spark' 카테고리의 다른 글
| [Spark] Spark local mode와 Cluster Manager 및 deploy mode(client, cluster) (2) | 2020.10.23 |
|---|---|
| [Spark] Spark Property 설정 (0) | 2020.10.19 |
| [Spark] Matrix의 Row를 전체 Vertex 개수로 두고 Col 기준으로 나누기 ( 중복 비허용 ) (0) | 2020.10.11 |
| [Spark] Matrix의 Row를 전체 Vertex 개수로 두고 Col 기준으로 나누기 ( 중복 허용 ) (0) | 2020.10.10 |
| [Spark] RDD 데이터를 saveAsTextFile 을 사용해 S3 에 저장하기 (0) | 2020.10.10 |
'Data/Spark' Related Articles
more

Comments