
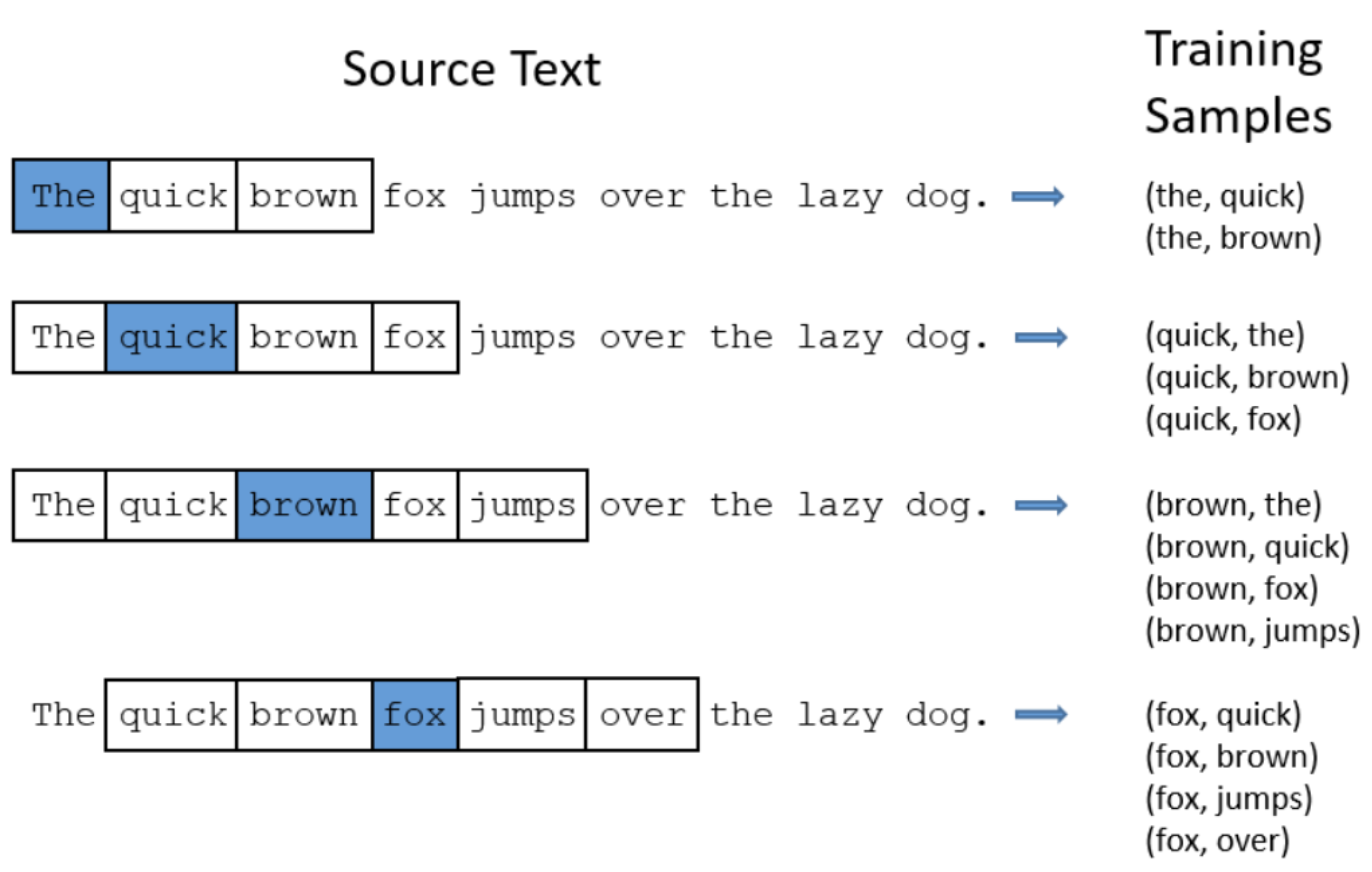
우노
[DL] Word2Vec, CBOW, Skip-Gram, Negative Sampling 본문
One-Hot Vector
- 기존의 자연어처리 분야에서는, 단어를 One-Hot Vector 로 표현했습니다.
- One-Hot Vector란, 예를 들어 사전에 총 10000개의 단어가 있고, Man이라는 단어가 사전의 5391번째 index에 존재한다면
- Man이라는 단어를, 5391번째 index만 1이고 나머지는 0인 10000차원 Vector로 표현하는 것입니다.
- 이 방법은 단순하다는 장점이 있지만,
- 단어를 단순히 index에 따른 Vector로 표현하기 때문에, 여러 단어 간 유사성을 평가할 수 없을 뿐만 아니라,
- 사전의 단어 개수가 증가하는 경우, One-Hot Vector의 크기가 지나치게 커진다는 단점을 가지고 있습니다.
- 따라서, 단어의 유사성을 파악할 수 있고, 저차원을 가지는 Vector를 만드는 방법이 Word Embedding입니다.
Word Embedding
- Word Embedding은, 단어를 특징을 가지는 N차원 Vector로 표현하는 것입니다.
- 예를 들어, 사전의 단어 개수가 10000개라면,
- One-Hot Vector는 각 단어를 [0,0,0,0,0,1,0,...,0] → 10000차원(사전개수) 으로 표현하지만
- Embedding Vector는 각 단어를 [1, 0.3, 0.5, 0.7, ..., 0.5] → 300차원(특징) 으로 표현하게 됩니다.
- 이렇게 단어를, 특징을 가지는 N차원 Embedding Vector로 만드는, Word Embedding 기법 중 하나가 Word2Vec 입니다.
Word2Vec
- Word2Vec은, 단어를 특징을 가지는 N차원 Embedding Vector로 만드는, Word Embedding 기법입니다.
- Embedding 시, 앞뒤 단어를 고려하기 때문에, 단어의 문맥상 의미까지 정량화된 벡터로 표현 가능합니다.
- Word2Vec은 CBOW 또는 Skip-Gram 알고리즘을 사용해 구현되는데,
- CBOW와 Skip-Gram은 서로 반대되는 개념으로 생각하면 됩니다.
Context (문맥)
컨텍스트란, CBOW와 Skip-Gram 모델에서 사용하는 용어로, "계산이 이루어지는 단어들"을 말합니다.
컨텍스트는 구둣점으로 구분되어지는 문장(sentence)을 의미하는 것이 아니라,
특정 단어 주변에 오는 단어들의 집합을 의미합니다.
- 예를 들어, "the cat sits on the"라는 문장이 있고,
- 해당 컨텍스트에서, 기준이 되는 단어(target word)를 'sits'으로 정하고
- 그와 가까운 위치에 함께 등장한 문맥 단어(context word)를 'the cat', 'on the'라고 한다면,
- 이들 단어를 모두 합친 5개의 단어가 컨텍스트가 되는 것입니다.
- 이 경우의 컨텍스트는, window size를 2로 설정하여, 목표 단어 양쪽에 2개의 단어만을 허용한 경우입니다.
- "the cat sits on the" 뒤에는 'mat'라는 추가 단어가 올 수 있지만, 컨텍스트에는 포함되지 않습니다.
이렇게 기준 단어와 문맥 단어를 정의하면,
CBOW는 문맥 단어를 보고 기준 단어가 무엇인지 예측하는 모델이고,
Skip-Gram은 기준 단어를 보고 어떤 문맥 단어가 등장할지 예측하는 모델로서,
아래와 같이 매우 간단한 단일 레이어 인공신경망 모형을 사용합니다.

즉, CBOW와 Skip-Gram은 매우 유사한 구조를 갖지만 입력(input)과 출력(output)이 서로 반대인 모델입니다.
두 모델은 입력으로 주어진 단어를 N차원의 벡터로 투영한 뒤,
이 벡터를 다시 소프트맥스(softmax) 함수를 이용해 출력 단어를 맞추도록 학습합니다.
CBOW (Continuous Bag-of-Words)

- CBOW는 컨텍스트가 주어졌을 때, 문맥 단어로부터 기준 단어를 예측하는 모델로써,
- 기준 단어에 대해 앞 뒤로 N/2개 씩, 총 N개의 문맥 단어를 입력으로 사용하여, 기준 단어를 맞추기 위한 네트워크를 만듭니다.
- 예를 들어, 다음 문장의 빈칸을 채우는 모델입니다.
- 운호는 냉장고에서 ____ 꺼내 먹었다.
- 예를 들어, 다음 문장의 빈칸을 채우는 모델입니다.
- 문장의 각 단어는 한 번의 업데이트 기회만 주어집니다.
- 예를 들어, 위 그림에서
- 첫 번째 줄의 'I'는 'like', 'playing'에 의해 업데이트
- 두 번째 줄의 'like'는 'I', 'playing', 'football'에 의해 업데이트
- 따라서, 문장의 각 단어는 한 번의 업데이트 기회만 주어지게 됩니다.
- CBOW는 크기가 작은 데이터셋에 적합합니다.
CBOW 학습 과정
CBOW의 학습과정을 예제를 통해 알아보겠습니다.

위 그림은, "The boy is going to school"에서 'The'를 기준단어, 'boy is going'를 문맥단어로 설정헤
문맥단어로부터 기준단어를 예측하는 CBOW 과정이며, 아래와 같은 순서로 진행됩니다.
1. (Input Layer) context에서 기준 단어를 제외한 문맥 단어 각각에 대해 one-hot vector를 만들어 input에 넣습니다.
- window size를 m으로 했을 경우, 2m개의 one-hot vector를 만들어 넣습니다.

2. (Input Layer → Hidden Layer) Input에 input word matrix를 곱해, N차원 embedding vector를 얻습니다.
- 문맥 단어 개수(2m)만큼의 N차원 embedding vector가 얻어집니다.
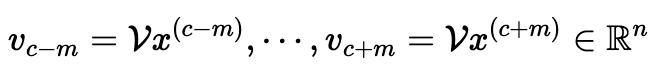
3. (Hidden Layer) 2의 결과인 N차원 embedding vector들을 평균 내 하나의 N차원 embedding vector를 만듭니다.

4. (Hidden Layer → Output Layer) 3의 결과를 output word matrix에 곱해, 입력 차원과 같은 vector를 만듭니다.

5. (Output Layer) 4에서 얻어진 vector를 균등한 확률로 표현하기 위해 softmax 함수를 취합니다.
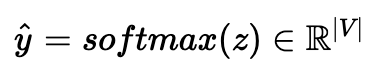
6. (Loss) y hat을 기준 단어의 one-hot vector인 y와 오차 측정합니다.
오차 측정 시 Cross-entropy loss가 사용되며,
학습할 word가 one-hot vector의 i 번째 위치한다면, i 번째 값만 1 이고 나머진 0 이기 때문에, 아래와 같이 나타낼 수 있습니다.

모든 가중치 집합을 θ라고 한다면 CBOW는 다음을 푸는 것과 같습니다.
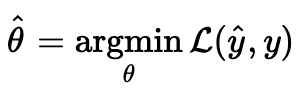
이어서 L을 자세히 살펴보겠습니다.

- Deep Learning과 마찬가지로 기울기 강하법으로 학습을 할 수 있습니다.
- 하지만 |V|가 커지면 계산량이 굉장히 커집니다.
- 이를 해결하기 위한 방법으로 negative sampling, hierachical softmax 방법이 제안되었습니다.
Skip-Gram
- Skip-Gram는 컨텍스트가 주어졌을 때, 기준 단어로부터 문맥 단어를 예측하는 모델로써,
- 기준 단어를 입력으로 사용하여, 기준 단어에 대해 앞 뒤로 N/2개 씩, 총 N개의 문맥 단어를 맞추기 위한 네트워크를 만듭니다.
- 예를 들어, 다음 문장의 빈칸을 채우는 모델입니다.
- _ ___ 음식을 __ ___.
- 예를 들어, 다음 문장의 빈칸을 채우는 모델입니다.
- 문장의 각 단어는 Context에 따라 여러번의 업데이트 기회가 주어집니다.
- Skip-Gram model은 크기가 큰 데이터셋에 적합합니다.
Skip-Gram 학습 과정
Skip-Gram의 학습과정을 예제를 통해 알아보겠습니다.

위 그림은, "The boy is going to school"에서 'The'를 기준단어, 'boy is going'를 문맥단어로 설정해
기준단어로부터 문맥단어를 예측하는 Skip-Gram 과정이며, 아래와 같은 순서로 진행됩니다.
1. (Input Layer) context에서 기준 단어에 대한 one-hot vector를 만들어 input 에 넣습니다.
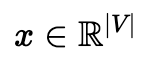
2. (Input Layer → Hidden Layer) Input에 input word matrix를 곱해, N차원 embedding vector를 얻습니다.

3. (Hidden Layer → Output Layer) 2의 결과인 N차원 embedding vector에 2m개의 output word matrix를 곱해, 입력 차원과 같은 vector를 만듭니다.
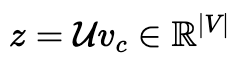
4. (Output Layer) 3에서 얻어진 vector를 균등한 확률로 표현하기 위해 softmax 함수를 취합니다.
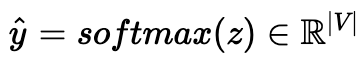
5. (Loss) y hat을 각 문맥 단어들의 one-hot vector인 y와 오차 측정합니다.
오차 측정 시 CBOW와 동일하게 Cross-entropy가 사용되며,

위 그림에서 문맥 단어는 2m개가 있으며, 각 문맥 단어는 c-j 번째 index가 1인 one-hot vector로 나타낼 수 있습니다.
Skip-Gram은 CBOW와 동일하게 아래 공식을 통해 가중치를 학습할 수 있습니다.

이어서 L을 자세히 살펴보겠습니다.

- Skip-Gram은 CBOW와 달리 문맥 단어들은 서로 독립이라는 가정이 추가됩니다.
- 하지만, |V|가 커지면 계산량이 굉장히 커진다는 점은 CBOW와 동일합니다.
Skip-Gram 학습 과정 요약
Skip-Gram 학습 과정은 아래 그림과 같이 요약할 수 있습니다.

CBOW vs Skip-Gram
현재는 CBOW보다 Skip-Gram이 더 많이 사용됩니다.
예제를 통해, 왜 Skip-Gram이 상대적으로 더 우세한지 알아보겠습니다.
아래 예제는 "The boy is going to school."을 context로 두어 CBOW와 Skip-Gram을 실행한 예제입니다.

CBOW는 문맥 단어로부터 1개의 기준 단어를 예측 및 학습하고
Skip-Gram은 기준 단어로부터 여러 문맥 단어를 예측 및 학습하기 때문에
Skip-Gram의 각 단어들은 여러 context에 걸쳐 빈번하게 학습되게 됩니다.
따라서, Skip-Gram이 대부분의 상황에서 더 좋은 성능을 보인다고 알려져있습니다.
Hierarchical Softmax와 Negative Sampling
CBOW와 Skip-Gram의 목적함수는 사전의 단어개수를 의미하는 |V|가 포함되어있어, 단어의 수가 많아짐에 따라 계산 복잡도가 높아진다는 단점이 있었습니다.
CBOW의 목적함수
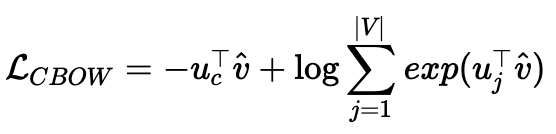
Skip-Gram의 목적함수
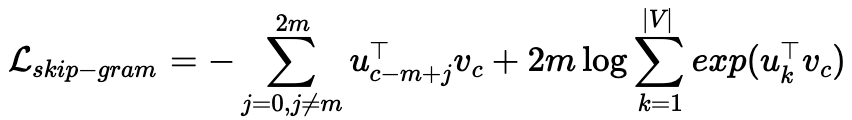
Hierarchical Softmax와 Negative Sampling은 이러한 계산 복잡도를 줄이기 위해 고안되었습니다.
이 두 가지 방법은 단순히 학습 단계의 목적함수를 대체하기 위한 테크닉입니다.
Hierarchical Softmax와 Negative Sampling가 적용되는 부분은 아래 그림과 같습니다.

Negative Sampling
Word2Vec 모델의 마지막 단계를 보면, 출력층 Layer에 있는 softmax 함수는 사전 크기 만큼의 Vector의 모든 값을 0과 1사이의 값이면서 모두 더하면 1이 되도록 바꾸는 작업을 수행합니다.
그리고 이에 대한 오차를 구하고, 역전파를 통해 모든 단어에 대한 임베딩을 조정합니다.
그 단어가 기준 단어나 문맥 단어와 전혀 상관 없는 단어라도 마찬가지입니다.
그런데 만약 사전의 크기가 수백만에 달한다면, 이 작업은 굉장히 무거운 작업입니다.
따라서, 이를 조금 더 효율적으로 진행하기 위해, 임베딩 조절시 사전에 있는 전체 단어 집합이 아닌, 일부 단어집합만 조정합니다.
이 일부 단어 집합은, positive sample(기준 단어 주변에 등장한 단어)와 negative sample(기준 단어 주변에 등장하지 않은 단어)로 이루어져있습니다.
- 즉, 기준 단어와 관련된 parameter들은 다 업데이트 해주는데, 관련되지 않은 parameter들은 몇 개 뽑아서 업데이트 해주겠다는 것입니다.
이 때, 몇 개의 negative sample을 뽑을지는 모델에 따라 다르며, 보통 문맥 단어개수 + 20개를 뽑는다고 합니다.
또한, negative sample은 말뭉치에서 빈도수가 높은 단어가 뽑히도록 설계되어 있으며, 공식은 아래와 같습니다.

- Wi : i번째 단어
- f(Wi) : 해당 단어의 빈도
- 즉, ( i번째 단어 출현 횟수 / 전체 단어 수 ) **3/4 이다.
- 3/4 제곱을 해주면 퍼포먼스가 더 좋아진다고 한다.
예를 들어, 이해해보겠습니다.
- "I live in Seoul and like data analysis."라는 문장이 있다면
- 'Seoul' 이라는 단어를 학습할 때, window size = 2 라고 가정할 경우, 주변 단어 (Positive sampling) 은 'live', 'in', 'and', 'like' 입니다.
- 이 때, negative sample 로써, Seoul의 이웃에 포함되지 않는 단어 (예를 들어, 'data' , 'analysis') 20개를 추가합니다.
- 이 때, 추가되는 것도 확률에 근거합니다.
참고
'AI > Deep Learning' 카테고리의 다른 글
| [DL] Semantic Segmentation (FCN, U-Net, DeepLab V3+) (8) | 2021.03.19 |
|---|---|
| [DL] Autoencoder (오토인코더) (0) | 2021.03.03 |
| [DL] One-Hot Vector, Word Embedding (1) | 2021.02.17 |
| [DL] RNN, LSTM, GRU 란? (5) | 2021.02.16 |
| [DL] Sequence Model이란? (3) | 2021.02.15 |



