
우노
[Hadoop] HDFS, MapReduce, YARN 개념 본문
Hadoop 구성 요소
- Hadoop은 다음 세 가지로 구성됩니다.
- 노드 클러스터에 광범위한 데이터를 저장하기위한 HDFS 파일 시스템
- 분산 계산을 위해 개발 된 MapReduce 프레임 워크
- 요청 된 작업에 사용 가능한 리소스를 할당하기위한 YARN
HDFS
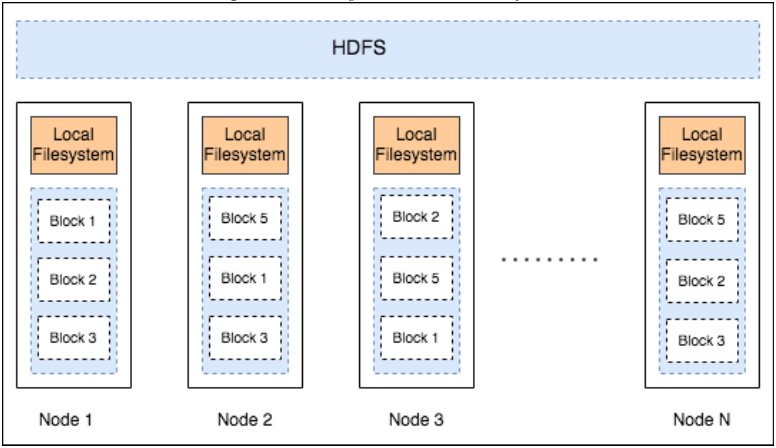
위 그림은, HDFS의 구조를 나타냅니다.
HDFS는 하둡 분산 파일 시스템의 약자로써, 대규모 데이터를 클러스터 내에 분산 저장하는 시스템입니다.
전체 데이터는 128MB 씩 분할 되어, 하나의 블록 내에 저장되며, 하나의 블록은 3개씩 다른 노드에 복제됩니다.
- 이 값은 기본값이며 변경할 수 있습니다.
따라서, 하나 이상의 노드가 서비스를 중단하면, 다른 노드에 저장된 데이터 복사본으로 부터 데이터를 가져올 수 있습니다.
HDFS는 클러스터 내부의 모든 노드들이 공유하는 파일 시스템이며, 각 노드 내에서 HDFS 디렉토리를 볼 수 있습니다.
- 각 노드의 로컬 파일 시스템과 HDFS 는 물리적으로 다른 위치에 있습니다.
또한, HDFS 는 메타데이터(클러스터 전체의 블록 위치, 파일과 폴더의 위치, etc )를 관리하는 전용 머신 인 Namenode 와 데이터 블록이 들어있는 Datanode 로 구성됩니다
하지만, Namenode 가 다운되면 전체 Hadoop 시스템이 다운됩니다.
따라서, 이 문제를 극복하기 위해 Hadoop은 아래 그림과 같은 구조로 발전했습니다.

- 두 개의 Namenode(Active Namenode, Standby Namenode)를 통해 Datanode와 통신하고 공유 폴더에 편집 로그를 저장합니다.
- 이름에서 알 수 있듯이 Active Namenode가 중단 될 때마다, Standby Namenode가 활성화되기 때문에, 서비스 중단이 발생하지 않습니다.
MapReduce
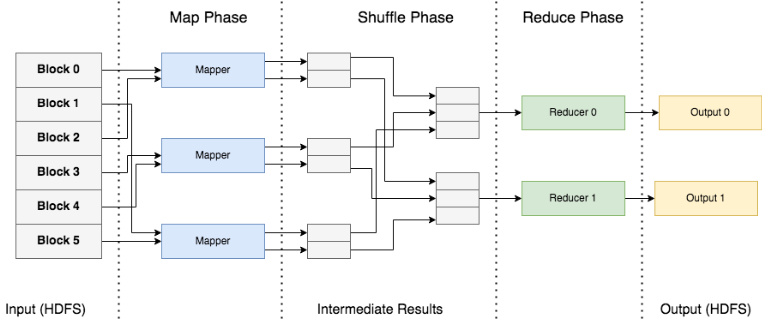
- 위 그림은, MapReduce 흐름이며
- 첫 번째로, HDFS 의 각 노드들에 있는 Data Block 이 Mapper 에 할당됩니다.
- 두 번째로, 계산 된 중간 결과가 Shuffle 됩니다.
- 계산은 관련 Data Block 이 있는 노드에서 이루어지며, 이는 데이터 지역성이라고 불립니다.
- 각 Data Block 이 저장된 노드의 로컬 리소스를 활용하여 계산을 실행하면,
- 계산을 위해 노드간에 데이터를 이동할 필요가 없게 됩니다.
- 계산은 관련 Data Block 이 있는 노드에서 이루어지며, 이는 데이터 지역성이라고 불립니다.
- 세 번째로, Suffle 된 데이터를 Reducer에게 전달해 마지막 계산을 진행합니다.
- 마지막으로, 계산 된 결과가 HDFS에 저장됩니다.
YARN

- YARN은 "Yet Another Resource Negotiator"의 약자이며,
- Storage(HDFS)와 Application(MapReduce) 간의 자원을 조절해주는 역할을 합니다.
'Data > Hadoop' 카테고리의 다른 글
| [Hadoop] hdfs 명령어 정리 (0) | 2021.08.24 |
|---|
Comments