
우노
[ML] Sklearn Polynomial Regression 본문
Linear Regression 이란?
Linear Regression 은 선형 회귀이며, 선형 방정식은 아래 공식으로 표현할 수 있습니다.
- y = ax + b
하지만, 아래 그림처럼, 데이터가 비선형적으로 분포하고 있을 땐, 선형 회귀 모델의 오차는 커지게 됩니다.
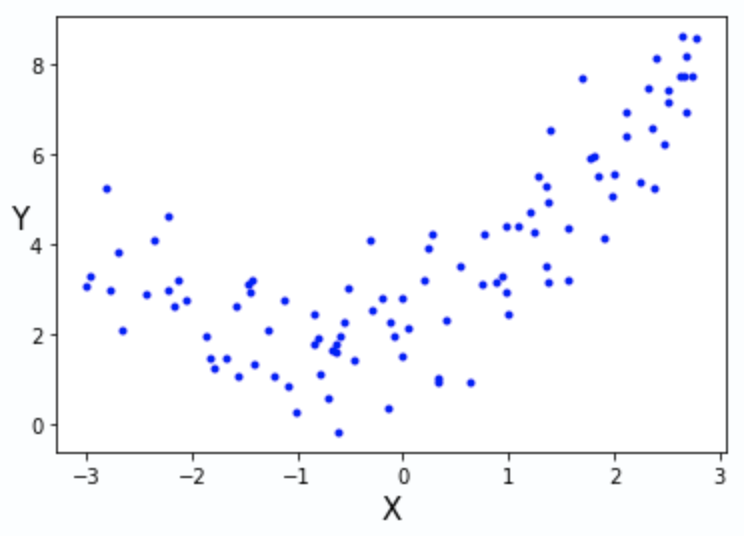
따라서 만약, 데이터가 2차원 곡선 형태로 분포되어 있다면, 2차원 곡선 모델로,
3차원 곡선 형태로 분포되어 있다면, 3차원 곡선 모델로 접근하는 것이 오차를 줄이는 방법일 수 있습니다.
Polynomial Regression 이란?
Polynomial Regression 은 다항 회귀이며, 다항 방정식은 아래 공식으로 표현할 수 있습니다.
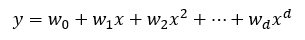
따라서, 데이터가 비선형적으로 분포하고 있을 땐, 아래 그림과 같이, 비선형 회귀 모델의 오차가 적어지게 됩니다.
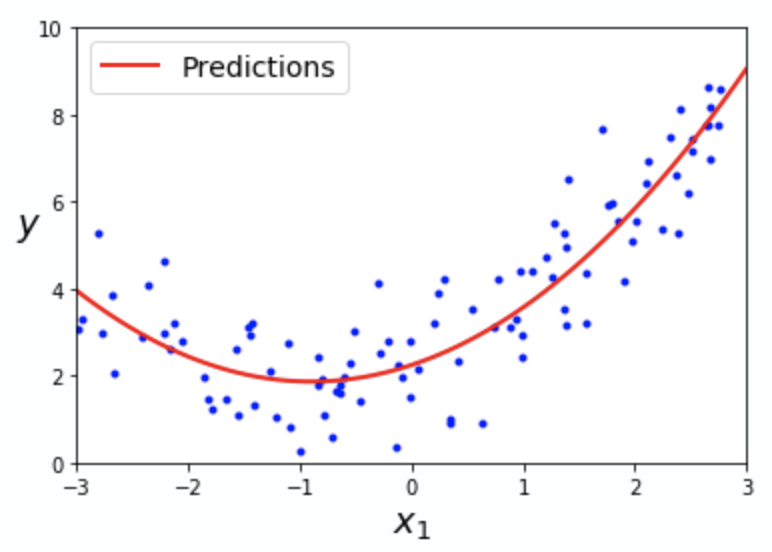
Sklearn 의 Polynomial Regression
- reference
- Sklearn 의 Polynomial Regression 모델은 비선형 데이터를 학습하기 위해, 선형 회귀 모델을 사용하는 기법입니다.
- 입력 데이터셋을 X 라고 가정했을 때,
- X 의 거듭제곱(X^2, X^3, etc)을 생성해, 입력 데이터셋에 새로운 변수로 추가하고,
- 이 확장된 변수를 포함한 데이터셋을 선형모델로 훈련시키는 방법입니다.
- 즉, X 를 통해 X^2, X^3 을 생성한 뒤, y = 1 + aX + bX^2 + cX^3 형식을 구성하고
- a, b, c 를 선형 회귀 모델을 통해 학습하는 방법입니다.
- 무슨 소리인지 코드를 통해 좀 더 쉽게 설명해보겠습니다.
예제 코드
훈련 데이터셋 X_train, y_train 생성
from sklearn.preprocessing import PolynomialFeatures X_train = np.arange(6).reshape(3, 2) # array([[0, 1], # [2, 3], # [4, 5]]) y_train = 0.5 * X_train**2 + X_train + 2 # array([[ 2. , 3.5], # [ 6. , 9.5], # [14. , 19.5]])훈련 데이터셋 X_train 의 거듭제곱을 생성한 뒤, 훈련 데이터셋 X_train 에 새로운 변수로 추가
# degree : 거듭제곱의 차수, include_bias : 편향값(1) 추가 여부 poly = PolynomialFeatures(degree=2, include_bias=True) # 훈련 데이터셋 X_train 의 거듭제곱을 생성한 뒤, 훈련 데이터셋 X_train 에 새로운 변수로 추가 X_train_poly = poly.fit_transform(X_train) # array([[ 1., 0., 1., 0., 0., 1.], # [ 1., 2., 3., 4., 6., 9.], # [ 1., 4., 5., 16., 20., 25.]])- 제곱 : ['1', 'x0', 'x1', 'x0^2', 'x0 x1', 'x1^2']
- 세제곱 : ['1', 'x0', 'x1', 'x0^2', 'x0 x1', 'x1^2', 'x0^3', 'x0^2 x1', 'x0 x1^2', 'x1^3']
- get_feature_names() 을 통해 만들어진 변수의 차수를 쉽게 확인할 수 있습니다.
확장된 변수를 포함한 훈련 데이터셋을 선형모델로 훈련
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X_train_poly, y_train)테스트 데이터셋 X_test, y_test 생성
X_test = np.linspace(-3, 3, 6).reshape(3, 2) # array([[-3. , -1.8], # [-0.6, 0.6], # [ 1.8, 3. ]]) y_test = 0.5 * X_test**2 + X_test + 2 # array([[3.5 , 1.82], # [1.58, 2.78], # [5.42, 9.5 ]])테스트 데이터셋 X_test 의 거듭제곱을 생성한 뒤, 테스트 데이터셋 X_test 에 새로운 변수로 추가
X_test_poly = poly.transform(X_test)테스트 데이터셋 예측
y_pred = lin_reg.predict(X_test_poly)
코드 요약
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
X_train = np.arange(6).reshape(3, 2)
y_train = 0.5 * X_train**2 + X_train + 2
poly = PolynomialFeatures(degree=2, include_bias=True)
X_train_poly = poly.fit_transform(X_train)
lin_reg = LinearRegression()
lin_reg.fit(X_train_poly, y_train)
X_test = np.linspace(-3, 3, 6).reshape(3, 2)
y_test = 0.5 * X_test**2 + X_test + 2
X_test_poly = poly.transform(X_test)
y_pred = lin_reg.predict(X_test_poly)참고
'AI > Machine Learning' 카테고리의 다른 글
| [ML] .h5 란? (2) | 2021.08.12 |
|---|---|
| [ML] Sklearn Permutation Importance 를 사용한 Feature 중요도 파악 (2) | 2021.07.21 |
| [ML] TfidfVectorizer를 사용한 Train, Test set 생성 (0) | 2021.05.26 |
| [ML] Isolation Forest (1) | 2021.03.08 |
| [ML] Feature Selection (Filter Method & Wrapper Method & Embedded Method) (2) | 2021.02.26 |
'AI/Machine Learning' Related Articles
more



Comments