
우노
[DL] Regularization (Dropout) 본문
Inverted Dropout
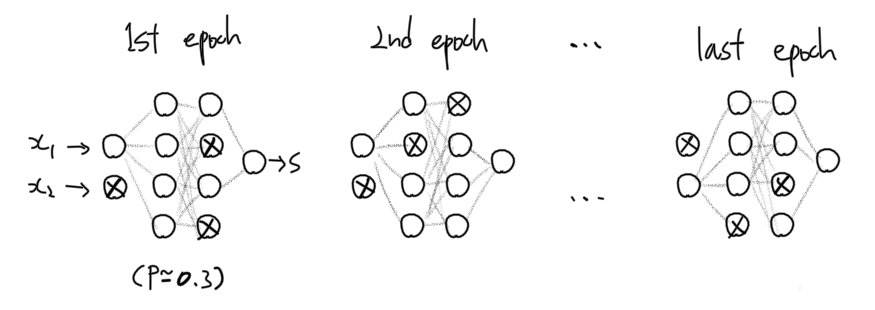
- dropout은 모델의 overfitting을 줄이는 방법 중 하나이다.
- overfitting을 줄이는 방법으로는 L1 Regularization, L2 Regularization, dropout 등이 있다.
- dropout의 사전적 의미는 탈락, 낙오이다.
- 즉, dropout은 deep learning 학습마다, 전체 노드를 계산에 참여시키는 것이 아니라, 일부의 노드만 계산에 참여시키는 것이다.
- 따라서, 참여되는 노드는 매 학습마다 달라지며
- 이렇게 학습시킨 신경망의 결과는, 마치 비슷하지만 서로 다른 여러개의 신경망 모형들의 결과를 평균낸 것과 유사한 형태가 된다.
- 신경망 여러개의 결과가 평균 내졌기 때문에, 일반적이지 않은 분류 결과가 제거되는 정규화 효과를 가진다.
순서
순전파 예제 코드
Z1 = np.dot(W1, X) + b1 # 선형 함수 A1 = relu(Z1) # 활성화 함수 D1 = np.random.rand(A1.shape[0],A1.shape[1]) # Step 1 D1 = (D1 < keep_prob).astype(int) # Step 2 A1 = A1*D1 # Step 3 A1 = A1/keep_prob # Step 4- Step 1
- np.random.rand()을 사용해 입력 레이어와 동일한 크기의 D1 행렬을 생성
- D1 행렬은 0~1 사이의 실수로 이루어져 있다.
- Step 2
- D1 행렬의 요소를 keep_prob 보다 작으면 0, 크면 1 로 전환한다. (마스크 행렬)
- Step 3
- D1 행렬과 A1 행렬을 곱해, A1 행렬의 요소들을 삭제한다.
- Step 4
- A1 행렬을 keep_prob으로 나눠, dropout 하지 않은 것처럼 A1 행렬을 조정해준다.
- A1 활성화함수 값이 줄어듬으로써, 다음 Z2의 기댓값이 감소하지 않게 하기 위해서이다.
- 예
- 기존 A1 활성화함수 값이 [1, 2, 3, 4] 라면 합은 10이다.
- dropout 이후 A1 활성화함수 값이 [0, 2, 0, 4] 라면 합/keep_prob (8/0.8) 은 10이므로, 기존의 A1 활성화함수 값과 동일하게 된다.
- Step 1
역전파 예제 코드
dZ3 = A3 - Y #z3의 gradient dW3 = 1./m * np.dot(dZ3, A2.T) #w3의 gradient db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True) #b3의 gradient dA2 = np.dot(W3.T, dZ3) #a2의 gradient dA2 = D2 * dA2 # Step 1 dA2 = dA2/keep_prob # Step 2- Step 1
- 순전파에서 사용했던 D2(마스크 행렬)를 동일하게 적용하여 동일한 뉴런을 삭제한다.
- Step 2
- 순전파와 동일한 이유로, dropout을 사용하지 않은 것 처럼 값을 조정해준다.
- Step 1
이 방식을 inverted Dropout이라고 하며, 일반적으로 dropout을 사용했다고 하면 열에 아홉은 inverted dropout을 사용했다는 말이다.
inverted가 아닌 dropout은 잘 사용하지 않는다.
'AI > Deep Learning' 카테고리의 다른 글
| [DL] Momentum, NAG, AdaGrad, RMSProp, Adam (0) | 2021.01.21 |
|---|---|
| [DL] 지수 가중 평균 (Exponentially Weighted Averages) (1) | 2021.01.20 |
| [DL] 가중치 초기화 (1) | 2021.01.19 |
| [DL] Gradient Checking (1) | 2021.01.18 |
| [DL] Regularization (L1, L2) (0) | 2021.01.18 |
'AI/Deep Learning' Related Articles
more




Comments