
우노
[ML] 배깅(Bagging), 부스팅(Boosting), 보팅(Voting) 본문
앙상블(Ensemble)
- 앙상블은 여러 개의 의사 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법입니다.
- 앙상블 학습의 핵심은, 여러 개의 약 분류기(Weak Classifier)를 병렬 또는 직렬로 결합하여 강 분류기(Strong Classifier)로 만드는 것입니다.
- 배깅 : 동일 알고리즘의 약 분류기를 병렬로 사용
- 부스팅 : 동일 알고리즘의 약 분류기를 직렬로 사용
- 보팅 : 다른 알고리즘의 약 분류기를 병렬로 사용
배깅(Bagging)

- 원본 데이터를 랜덤 샘플링해, 크기가 동일한 n개의 샘플 데이터를 생성하고
- 각 샘플 데이터를 기반으로 동일한 알고리즘 기반의 의사 결정 트리를 병렬적으로 학습한 뒤,
- 각 모델의 학습 결과를 결합하는 방식입니다.
- 일반적으로 학습 결과를 결합할 때,
- 회귀 문제라면 평균(average),
- 분류 문제라면 다중 투표(majority vote)가 사용됩니다.
- 대표적인 배깅 모델로는 'Random Forest'가 있습니다.
부스팅(Boosting)
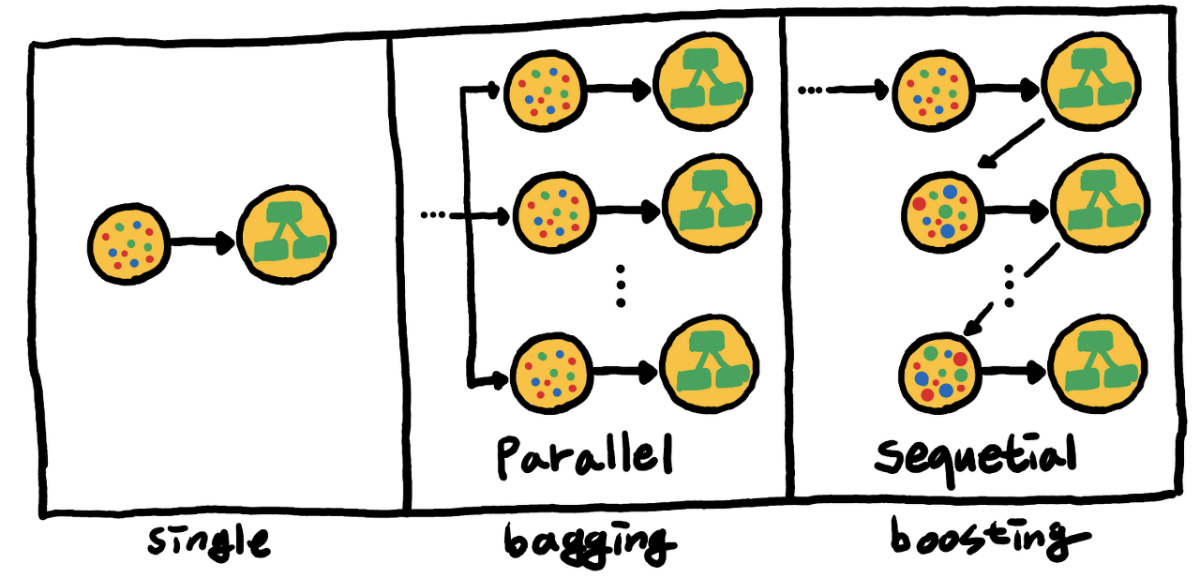
- 부스팅 알고리즘은 위 그림의 가장 우측과 같이 표현될 수 있습니다.
- 위 그림에서 나타내는 바와 같이, 배깅은 병렬로 학습하는 반면, 부스팅은 순차적으로 학습합니다.
- 즉, n 번째 Weak Tree 의 학습 결과가 n+1 번째 Weak Tree 의 학습에 영향을 주게 됩니다.
- 그렇다면 어떻게 영향을 줄 수 있을까요?
- 바로, 샘플링에서 영향을 주게 됩니다.
- 부스팅은, 각 부스팅 단계를 진행하며, 분류가 어려운 샘플 데이터를 확인하고
- 해당 샘플 데이터에 가중치를 할당함으로써, 이후 부스팅 단계에서 해당 데이터가 재샘플링 될 확률을 높입니다.
- 따라서, 이후의 Weak Tree 들은 해당 데이터들을 더 잘 학습할 수 있게 됩니다.
- 뿐만 아니라, 최종 결과를 도출하는 과정에서도,
- 더 잘 학습한 의사 결정 트리에 더 많은 가중치를 할당함으로써, 더 많은 영향력을 주게 됩니다.
- 대표적인 부스팅 모델은 'AdaBoost', 'CatBoost', 'Gradient Boost', 'XGBoost' 등이 있습니다.
- XGBoost 는 병렬화를 시킴으로써 속도를 향상시켰습니다.
보팅(Voting)
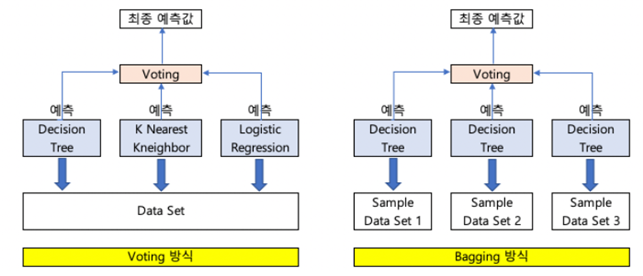
- Bagging 은 동일한 알고리즘 기반의 여러 Decision Tree 를 사용하지만
- Voting 은 다른 알고리즘 기반의 여러 Decision Tree 를 사용합니다.
참고
'AI > Machine Learning' 카테고리의 다른 글
| [ML] Model compile() - 학습과정 설정 (0) | 2020.08.06 |
|---|---|
| [ML] Metric 종류 (0) | 2020.08.06 |
| [ML] XGBoost 개념 이해 (10) | 2020.08.04 |
| [ML] 데이터 스케일링 (Data Scaling) 이란? (8) | 2020.08.03 |
| [ML] Epoch, Batch size, Iterations 용어 정리 (0) | 2020.07.30 |
'AI/Machine Learning' Related Articles
more


Comments