
우노
[추천시스템] 유사도(Similarity) 구하는 방법 본문
유사도 (Similarity)
- 드라마를 예시로 들었을 때, 두 드라마의 유사도를 어떻게 측정할 수 있을까?
- 장르나 키워드가 비슷하면 비슷하다. ( 자카드 유사도 )
- 보이스 (범죄, 스릴러, 다크, 서스펜스)
- 터널 (스릴러, 다크, 서스펜스)
- 사람들의 평가가 비슷하면 비슷하다. ( 평가 유사도 )
- 사람 1의 영화1 평가 (0.5점)
- 사람 2의 영화2 평가 (0.6점)
- 장르나 키워드가 비슷하면 비슷하다. ( 자카드 유사도 )
자카드 유사도 (Jaccard Similarity)
-
자카드 유사도
-
키워드를 통해 두 집합이 얼마나 비슷한지를 측정
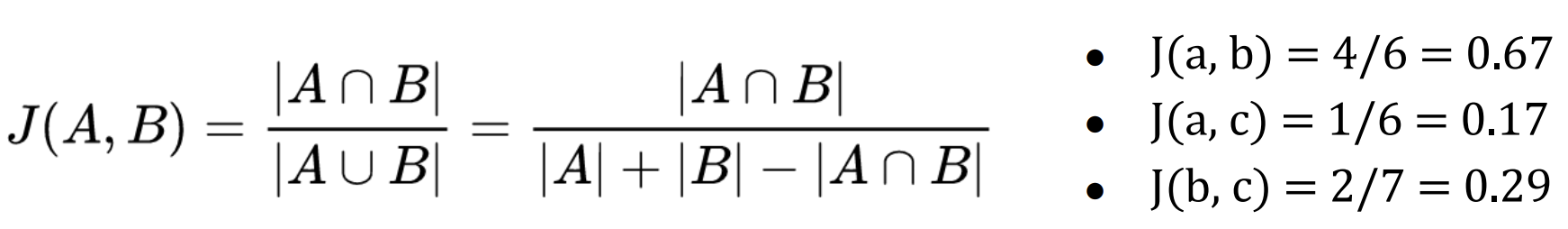
- 분자
- 두 집합의 교집합을 뽑는다.
- 분모
- 두 집합의 합집합을 뽑는다.
- 집합의 사이즈가 커지면 커질수록 패널티를 먹는다.
- 분자
-
예제
- 보이스 (범죄, 스릴러, 다크, 서스펜스)
- 터널 (스릴러, 다크, 서스펜스)
- 교집합 / 합집합 = 3/4
-
-
하지만 장르나 키워드가 명시적으로 주어져 있지 않다면?
-
우리가 줄거리나 설명글 등에서 키워드를 뽑아내야한다.
-
중요한 단어만을 뽑아내야 하는데 어떤 단어가 중요한 단어일까?
-
이 때 사용하는 알고리즘이 TF-IDF 이다.
-
TF-IDF
-
fij= 문서 i에서 단어 i가 등장한 빈도수
-
ni = 단어 i가 등장한 문서 수
-
N = 전체 문서 수
-
TF (Term-Frequency)

- 어떤 단어가 한 개의 Document에서 몇 번 등장하는지
- 한 개의 Document에서 해당 단어 등장 횟수 / 한 개의 Document에 가장 많이 등장한 단어 개수
-
IDF (Inverse Document Frequency)

- ni / N 은 숫자가 높을수록 여러 개의 문서에서 단어가 등장한 것
- 여러 문서에 단어가 등장 할수록 중요한 단어가 아니기 때문에 ni / N 을 역수로 사용한다.
- 역수를 사용하면 단어가 등장한 문서 개수가 작아질수록 값이 커지게 된다.
- 따라서 N / ni 값이 클수록 중요한 단어이다.
-
따라서, 각 줄거리마다 TF-IDF Score가 가장 높은 단어 몇 개를 키워드로 뽑아 자카드 유사도를 구하면 된다.
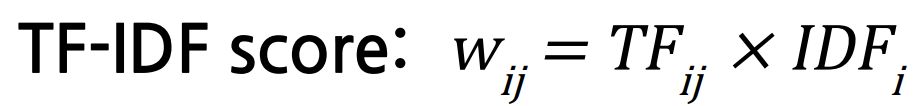
-
-
평가 유사도
-
키워드를 뽑지 않고 사람들이 매긴 평점 데이터만으로도 어느 정도의 유사도를 측정할 수 있다.
-
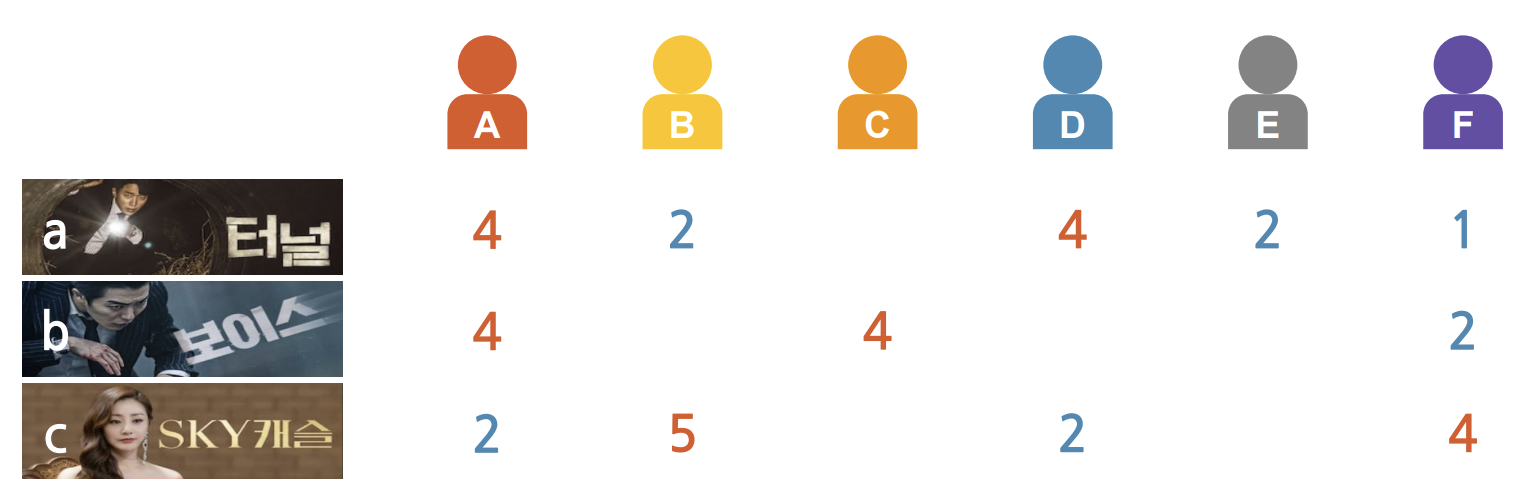
아래 그림은 A,B,C,D,E,F의 각 드라마 별 평점을 Vector로 표현한 것이다.
-
과연 보이스, SKY 캐슬 중 터널과 더 비슷한 드라마는 무엇이며
-
유사도를 어떻게 측정하면 될까?
-
-
이 때 사용하는 방법이 코사인 유사도이다.
-
코사인 유사도 (Cosine Similarity)
-
드라마에 대한 각 평점을 Vector로 봤을 때, 각 Vector가 비슷한 방향을 가지고 있다면 유사하다고 볼 수 있다.
- 즉, 두 Vector가 이루는 각도가 작을수록 유사하기 때문에 코사인 유사도를 사용한다.
-
각 드라마의 평점 Vector를 생성할 때, 평가가 안 된 빈칸들을 0으로 할당한 뒤 코사인 유사도를 구해보자.

- 실제론 a,b가 a,c보다 유사하다.
- 하지만 결과값은 a,c의 유사도가 a,b의 유사도 보다 높다. 왜 그럴까?
- 바로 사용자가 평가하지 않은 경우에 0점을 부여했기 때문이다.
- 점수가 0점이라는 것은 사용자가 보긴 했지만 최악의 점수를 준 것으로 계산된다.
- 따라서 0 대신 평균 점수를 부여해야한다.
- 이를 Centered Cosine Similarity 라고 한다.
-
-
Centered Cosine Similarity
-
각 드라마의 평점 Vector를 생성할 때, 평가가 안 된 빈칸들을 평균점수로 할당한 뒤 코사인 유사도를 구해보자.

- 이제 a,b가 a,c 보다 값이 크긴 하다. 하지만 왜 a,c와 b,c가 양수일까?
- 모든 평점이 긍정적이기 때문이다.
- 따라서, 모든 평점을 평균 점수만큼 빼준다.
- 이제 a,b가 a,c 보다 값이 크긴 하다. 하지만 왜 a,c와 b,c가 양수일까?
-
이제, 평가가 안 된 빈칸들을 평균점수로 할당한 뒤
-
모든 평점을 평균 점수만큼 빼주자.
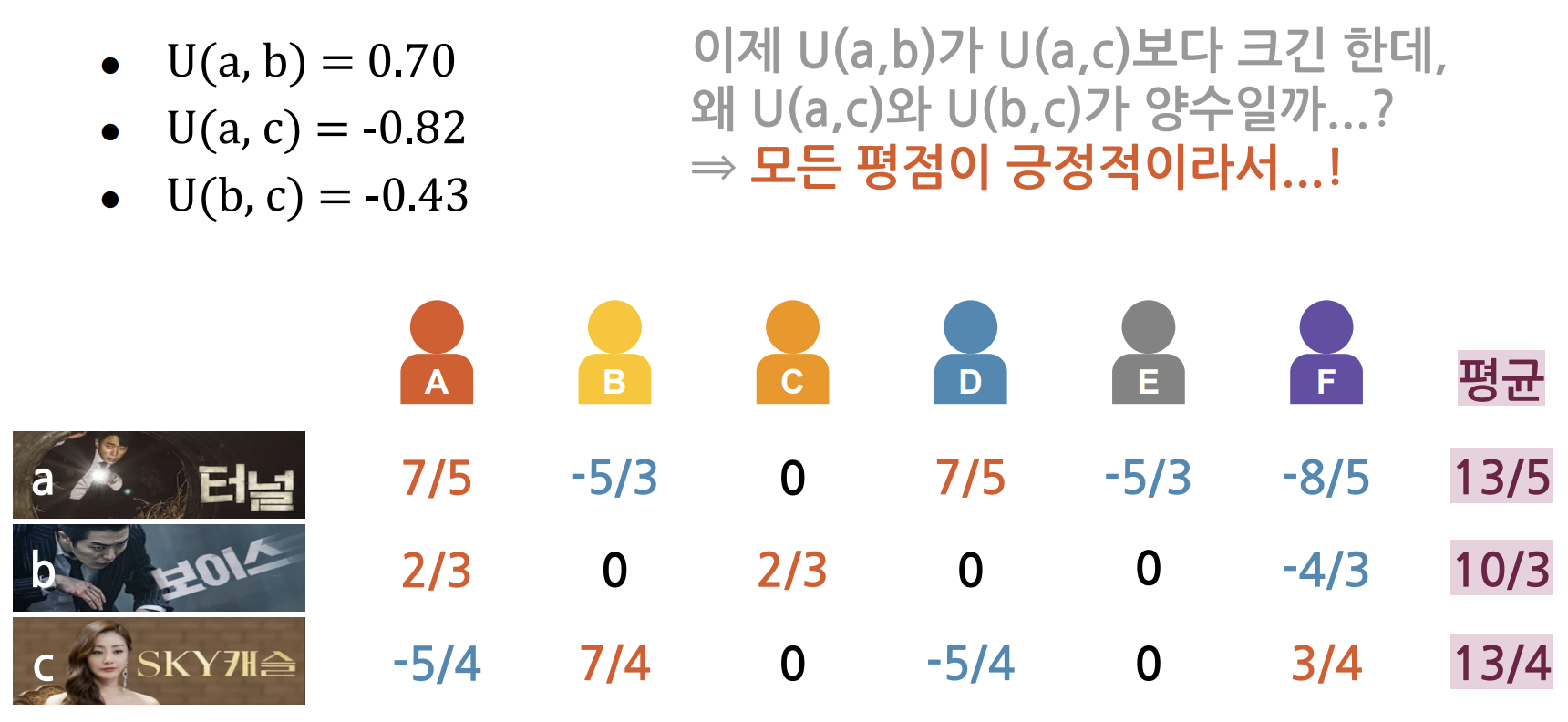
- a,b의 유사도는 양수 a,c의 유사도는 음수를 나타나게 된다.
-
추천하기
-
이제 내가 가장 재밌게 본 드라마 a와 유사도가 가장 높은 드라마 n개를 추천해야한다.
-
위에서 자카드 유사도(J(a,x))와 평가 유사도(U(a,x))를 구했으므로 이 두 가지를 섞어 유사도를 계산한다.
-
단순한 방법은 두 가지의 유사도에 원하는 가중치를 설정해 값을 도출하는 방법이다.

-
'Data > Recommender System' 카테고리의 다른 글
| [추천 시스템] Tensor Decomposition (0) | 2021.12.04 |
|---|---|
| [추천시스템] Latent Factor Model with Pytorch (0) | 2020.10.29 |
| [추천시스템] Latent Factor Model (1) | 2020.10.29 |
| [추천시스템] 유사도(Similarity) 튜토리얼 (0) | 2020.10.22 |
| [추천시스템] 추천 시스템의 개념 및 알고리즘 (0) | 2020.10.16 |

