
우노
[DL] 배치 정규화(Batch Normalization) 본문
- 기존에는 Gradient Vanishing, Exploding 현상을 해결하고 학습을 안정화하기 위해서 새로운 활성화 함수를 찾거나 가중치를 초기화하는 방법을 사용했었다.
- 하지만, 배치 정규화를 통해서 보다 근본적으로 학습과정을 안정화할 수 있고 빠르게 할 수 있다.
배치 정규화 (Batch Normalization, BN)
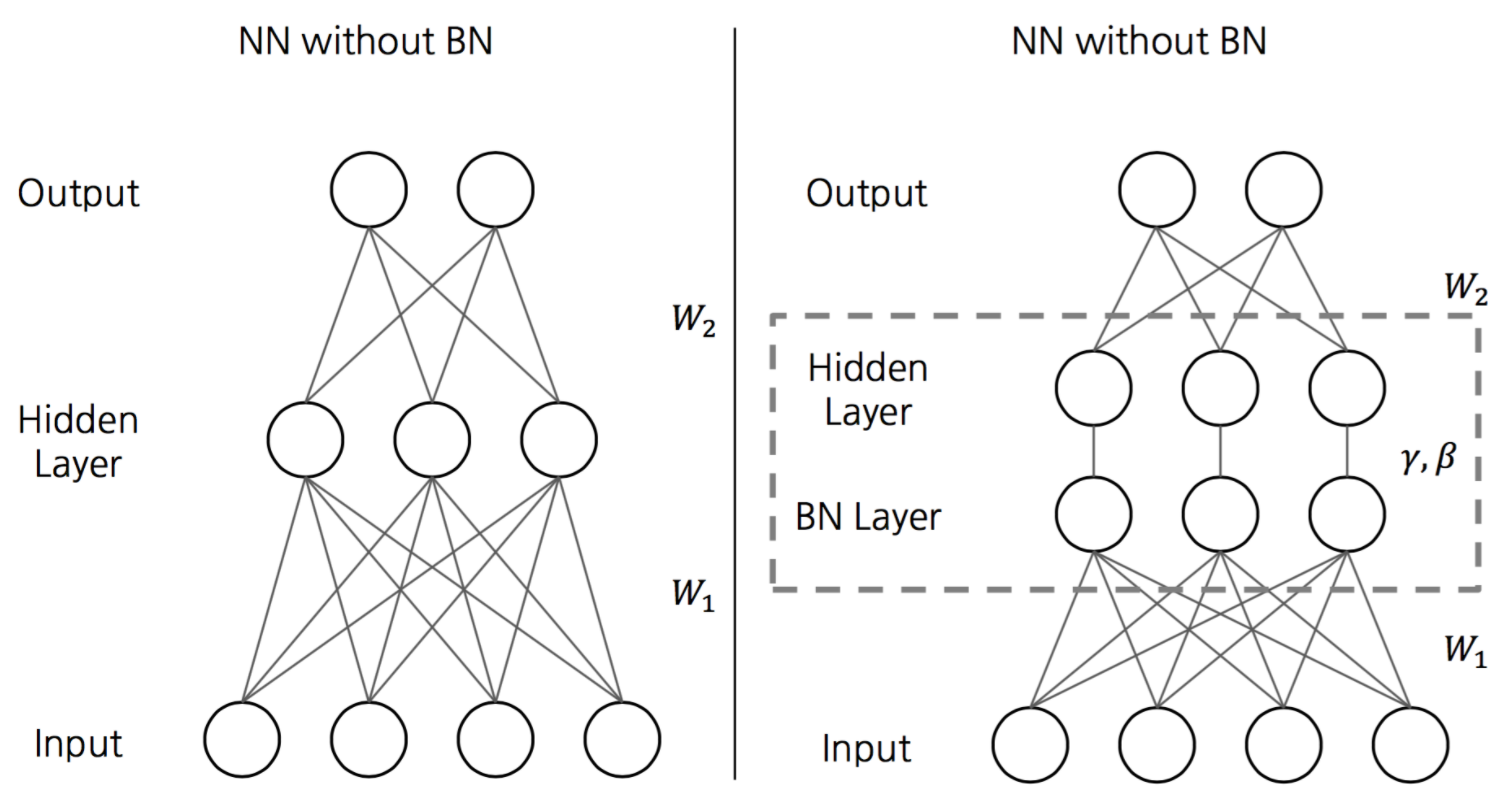
- 배치라는 단어는 전체 데이터에서 일부분을 칭하는 단어이다.
- 신경망을 학습시킬 때, 보통 전체 데이터를 한 번에 학습시키지 않고, 조그만 단위로 분할해서 학습을 시키는데, 이 때 조그만 단위가 배치이다.
- 큰 사이즈의 데이터를 한 번에 학습시키는 것은 시간이 오래걸린다.
- 따라서, 배치 단위로 정규화하는 것을 배치 정규화라고 부른다.
- 배치들은 학습을 진행하며, 각 layer의 활성화함수 입력값 또는 출력값에서 정규화된다.
- 배치 정규화를 활성화함수 이전에 하는지 이후에 하는지는 계속된 논의와 실험이 진행중이라고 한다.
이론

- 깊은 신경망일수록 같은 Input 값을 갖더라도, 가중치가 조금만 달라지면 완전히 다른 값을 얻을 수 있다.
- 이를 해결하기 위해, 각 layer에 배치 정규화 과정을 추가해준다면, 가중치의 차이를 완화하여 보다 안정적인 학습이 이루어질 수 있다.
알고리즘

배치 정규화 알고리즘은 간단하다.
먼저, hidden layer의 활성화함수 입력값or출력값 상태인 배치의 평균과 분산을 계산한다.
이후, 해당 배치를 평균 0, 분산 1이 되도록 정규화한다.
- 엡실론은 분모가 0 이 되는 것을 막기 위한 아주 작은 숫자(1e-5)이다.
정규화 이후, 배치 데이터들을 scale(감마(γ)), shift(베타(β)) 를 통해 새로운 값으로 바꾼다.
데이터를 계속 정규화 하게 되면, 활성화 함수의 비선형 성질을 잃게 되는 문제가 발생한다.
예를 들면, 아래 그림과 같이 Sigmoid 함수가 있을 때, 입력 값이 N(0, 1) 이라면, 95% 의 입력 값은 Sigmoid 함수 그래프의 중간 (x = (-1.96, 1.96) 구간)에 속하게 된다.

해당 부분이 선형이기 때문에, 비선형 성질을 잃게 되는 것이다.
하지만, 감마(γ), 베타(β)를 통해 활성함수로 들어가는 값의 범위를 바꿔줌으로써, 비선형 성질을 보존하게 된다.
감마(γ), 베타(β) 값은 학습 가능한 변수이며, Backpropagation을 통해서 학습이 된다.
테스트 단계
테스트 단계나 추론 단계에서는 평균과 분산을 계산할 미니배치가 없기 때문에, 전체 Training Set의 평균과 분산을 사용한다.
하지만, 엄청나게 많은 전체 Training set에 대한 평균과 분산을 계산하는 것은 무리이기 때문에,
아래의 식과 같이 모델 학습 단계에서 사용한, 각 n개의 미니배치에 대한 평균과 분산을 이용해, 전체 Training Set의 평균과 분산을 대신할 수 있다.

하지만, 위와 같은 방법 대신, 미리 저장해둔 n개의 미니 배치의 이동 평균을 사용하여 해결한다.

- 이러한 이동 평균과 분산을 위해, 모델 학습 단계에서 매 미니배치마다 이동 평균과 분산을 저장해놔야한다.
- 그래야 테스트 시, 모델 학습 단계에서 저장한 이동 평균과 분산을 사용할 수 있다.
- 위의 식에서 α값은 일반적으로 1에 가까운 0.9, 0.99, 0.999로 설정한다.
'AI > Deep Learning' 카테고리의 다른 글
| [DL] Transfer Learning(전이학습)이란? (3) | 2021.01.27 |
|---|---|
| [DL] End-to-End Deep Learning 이란? (6) | 2021.01.27 |
| [DL] Momentum, NAG, AdaGrad, RMSProp, Adam (0) | 2021.01.21 |
| [DL] 지수 가중 평균 (Exponentially Weighted Averages) (1) | 2021.01.20 |
| [DL] Regularization (Dropout) (0) | 2021.01.19 |

