
우노
[DL] LeNet-5, AlexNet, VGG-16, ResNet, Inception Network 본문
[DL] LeNet-5, AlexNet, VGG-16, ResNet, Inception Network
운호(Noah) 2021. 2. 3. 13:14-
CNN 종류는 다음과 같습니다.
- Classic Networks
- LeNet-5
- AlexNet
- VGG-16
- ResNet
- Inception(GoogLeNet) Network
- Classic Networks
-
들어가기 앞서, 입력 이미지 크기로부터 출력 이미지 크기를 추론하는 공식은 Convolution layer와 Pooling layer 모두 동일하며 아래와 같습니다.
- (n, n, c) 이미지에 대해 p 만큼 패딩한 후, c' 개의 (f, f, c) 필터 블록으로 s 씩 건너띄며 컨볼루션 한다면,
- 출력 이미지의 크기는 ((n+2p-f)/s+1, (n+2p-f)/s+1, c') 가 됩니다.
- (N+2p-f)/s + 1 가 실수라면 소수점 아래 부분은 버립니다.
LeNet-5

- LeNet-5은 손글씨 숫자를 인식하는 네트워크입니다.
- LeNet-5는, 하나 이상의 Convolution Layer와 Pooling Layer를 반복하고, 마지막에 Fully Connected Layer를 거쳐서 결과를 출력하는 것입니다.
- 특징
- LeNet-5의 입력 이미지는 그레이 채널만 가지고 있기 때문에, (32, 32, 1) 구조를 가지고 있습니다.
- Padding 없이 Convolution Layer를 사용하기 때문에 신경망이 깊어질수록 이미지 크기가 줄어듭니다.
- Convolution Layer와 Pooling Layer 단위마다 필터가 증가하므로, 신경망이 깊어질수록 Channel이 늘어납니다.
- Average Pooling을 사용합니다.
- 활성화 함수로 시그모이드를 사용합니다.
AlexNet

- AlexNet은 LeNet-5와 유사하게, 하나 이상의 Convolution Layer와 Pooling Layer를 반복하고, 마지막에 Fully Connected Layer를 거쳐서 결과를 출력합니다.
- 신경망이 깊어질수록 이미지의 크기는 줄어들고 채널은 늘어난다는 것은 LeNet-5와 동일하지만, LeNet-5에 비해 신경망이 훨씬 더 큽니다.
- 병렬 계산에 특화된 GPU의 보급으로 대량 연산을 고속으로 수행할 수 있게 되면서, AlexNet을 시작으로 딥러닝이 주목받기 시작했습니다.
- 특징
- 입력 이미지의 크기가 크기 때문에, 신경망 초반에 Convolution layer의 stride 값을 크게 주어 이미지 크기를 줄였습니다.
- Max Pooling을 사용합니다.
- Dropout을 사용합니다.
- 활성화 함수로 ReLU를 처음 사용했습니다.
VGG-16

-
VGG-16은 많은 파라미터를 가지고 있는 대신에, 더 단순한 네트워크입니다.
-
VGG-16는 Convolution Layer (filter = (3, 3), stride = 1, padding = same)와 Pooling Layer (filter = (2, 2), stride = 2)를 반복적으로 사용합니다.
- same padding이란, 입력 이미지의 크기와 출력 이미지의 크기가 동일하도록 만드는 padding 값을 사용하는 것입니다.
-
이미지의 채널은 Convolution Layer마다 2배씩 증가하며, 이미지 크기는 Pooling Layer마다 2배씩 감소합니다.
-
따라서, VGG-16 Network는 네트워크가 균일하고 단순하기 때문에 매력적입니다.
-
특징
- Max Pooling을 사용합니다.
- 활성화 함수로 ReLU를 사용합니다.
- 16개의 Layer를 사용하기 때문에 VGG-16 입니다.
-
단점
- Fully Connected Layer에서 parameter 수가 많습니다.
- 상당한 memory cost, overfitting 문제를 야기할 수 있습니다.
ResNet
-
ResNet은 마이크로소프트에서 개발한 알고리즘이며 깊은 신경망을 제공합니다.
-
깊은 신경망은 Vanishing Gradient, Exploding Gradient와 같은 문제가 발생하기 때문에, 학습시키기가 어렵습니다.
-
이 문제를 해결하기 위해, 저자들은 Residual Block 이라는 개념을 도입했으며
-
ResNet은 Residual Block의 집합으로 구성되어있습니다.
-
Residual Block
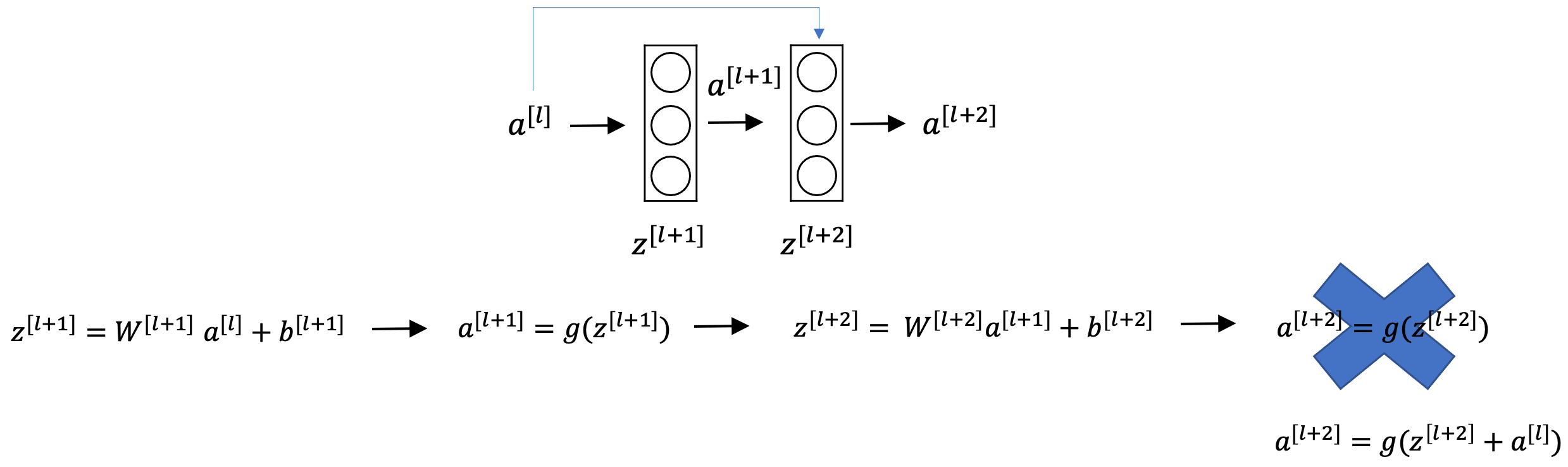
- 위 그림이 Residual Block을 나타냅니다.
- 기존의 망과 차이가 있다면, l+2번째 비선형 함수 입력값에 l 번째 비선형 함수 출력값을 더해줄 수 있도록 지름길(shortcut)을 하나 만들어주는 것입니다.
- l 번째 비선형 함수 출력값 a[l]이 2개의 Layer를 건너띄어 a[l+2]로 전달되기 때문에,
- a[l+2] = g(z[l+2]) 공식은 a[l+2] = g(z[l+2] + a[l]) 로 바뀌게 됩니다.
- 따라서, a[l+2]를 구하기 위해선 Z[l+2]와 a[l]이 필요하게 됩니다.
- 이 때, 만약 z[l+2] = W[l+2]*a[l+1] + b[l+2]에서 W와 b가 소실되어 z[l+2]가 0이 되어도,
- l 번째 비선형 함수 출력값 a[l] 은 남아있으므로
- Vanishing Gradient, Exploding Gradient 등의 문제를 해결하게 됩니다.
-
ResNet의 구조

- ResNet은 기본적으로 VGG-19의 구조를 뼈대로 합니다.
- VGG-19의 구조에 컨볼루션 층들을 추가해서 깊게 만든 후에, shortcut들을 추가하는 것이 사실상 전부입니다.
- 따라서, 34개의 layer를 가진 34-layer residual 네트워크와
- shortcut들을 제외한 버전인 34-layer plain 네트워크의 구조는 위 그림과 같습니다.
- ResNet 모델은 처음을 제외하고는 (3, 3) Convolution Layer를 균일하게 사용합니다.
- 그리고 이미지의 크기가 반으로 줄어들었을 땐, 채널의 크기를 2배로 늘려줍니다.
Inception Network를 위한 사전 지식
- Inception Network를 다루기 전에, 다음 2가지 개념을 알고 가야합니다.
- 1 x 1 Convolution
- Inception Module
1 x 1 Convolution
-
1 x 1 컨볼루션은 무엇일까요?
-
아래 그림은, (6, 6, 32) 볼륨에 (1, 1, 32) Convolution을 적용한 예제입니다.

- (1 x 1 x 32) Convolution은, 왼쪽 볼륨의 36가지 위치를 각각 살펴보며,
- 각 위치에 따라, 볼륨의 32개 채널 숫자와 필터의 32개 채널 숫자 간 곱셈을 하며 진행됩니다.
-
(1 x 1 x channel) Convolution이 유용하게 쓰이는 예시를 하나 더 들어보겠습니다.
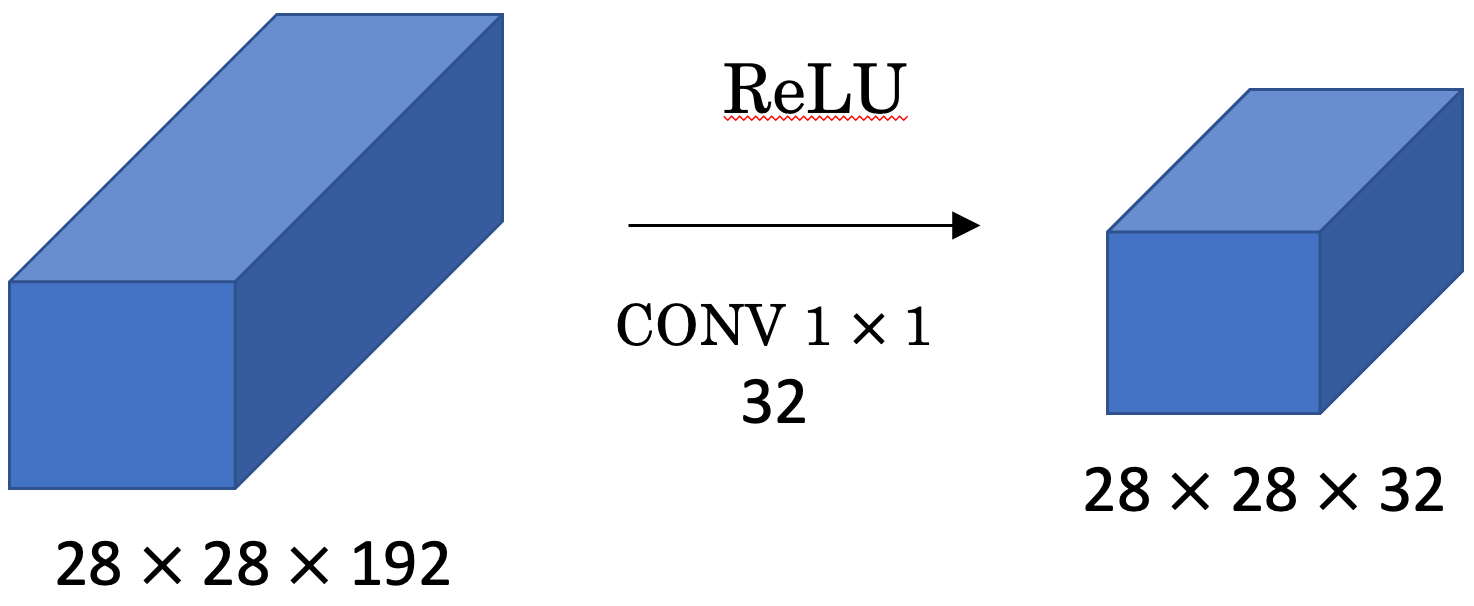
- 위 그림은, (28, 28, 192) 볼륨에 (1, 1, 192) Convolution을 적용한 예제입니다.
- 그 동안, 볼륨의 크기를 줄이기 위해서는 Pooling Layer를 사용했었습니다.
- 그렇다면, 볼륨의 크기는 그대로 둔 체, 채널을 줄이는 방법은 무엇이 있을까요?
- 바로, (1, 1, channel) Convolution을 사용하면 채널을 쉽게 줄일 수 있습니다.
- 위 그림처럼, (28, 28, 192) 볼륨에 (1, 1, 192) 필터 블록을 32개 적용한다면, 출력 볼륨은 (28, 28, 32)가 됩니다.
- 즉, n = 28, f = 1, p = 0, s = 1 이기 때문에
- 출력 볼륨의 크기는 (n+2p-f)/s+1 = 28 이 됩니다.
- 따라서, 1 x 1 컨볼루션을 사용하면 채널의 수를 줄일수도, 유지할수도, 늘릴수도 있게 됩니다.
Inception Module
-
Inception Network의 기본 아이디어인 Inception Module에 대해 알아보겠습니다.
-
Inception Module은 아래 그림처럼, input 볼륨에 대해
-
Convolution(1x1, 3x3, 5x5)과 Max-Pooling(3x3)을 각각 수행해서 output에 쌓아올리는 것을 말합니다.

- 위 그림에서, (28, 28, 192) 입력 볼륨은 Inception Module을 통해 (28, 28, 256) 출력 볼륨을 갖게 됩니다.
-
Inception Module은 파라미터와 필터 사이즈 조합을 모두 학습합니다.
-
하지만, 이러한 방법으로는 연산량이 너무 많아진다는 단점이 있습니다.
-
위 그림에서, (28, 28, 192) 볼륨에 대한 (5, 5) Convolution의 연산량이 얼마나 되는지 알아보겠습니다.

- 위 그림에서 same이란, 컨볼루션 이후 이미지 크기가 줄어들지 않도록 적절한 padding 값을 사용한다는 것이며, 32는 사용하는 필터 블록의 개수를 의미합니다.
- 출력의 볼륨은 (28, 28, 32) 이며, 각 출력에 대해 (5, 5, 192) 필터를 적용하므로, 총 28x28x32x5x5x192 = 1억2천만번의 연산이 수행됩니다.
- 하지만, 1 x 1 Convolution을 적용한다면 연산량을 10배 정도 감소시킬 수 있습니다.
-
따라서, (28, 28, 192) 볼륨에 대한 (1, 1) Convolution의 연산량이 얼마나 되는지 알아보겠습니다.

- 이전의 (5, 5) Conv 연산 중간에 (1, 1) Conv 연산을 추가했습니다.
- 따라서, bottleneck layer(병목층)이라고 부르기도 합니다.
- 중간 과정을 통해, 입력 볼륨을 16채널로 감소시키고, (5, 5) Conv 연산을 진행하게 되며
- 연산량은 28x28x16x1x1x192(1x1 conv 연산) + 28x28x32x5x5x16(5x5 conv 연산)으로 2.4M + 12.4M = 1240만입니다.
- 1억2천만에서 약 10배정도 감소된 것을 확인할 수 있습니다.
-
따라서, Inception Module은 아래 그림과 같은 구조를 띕니다.
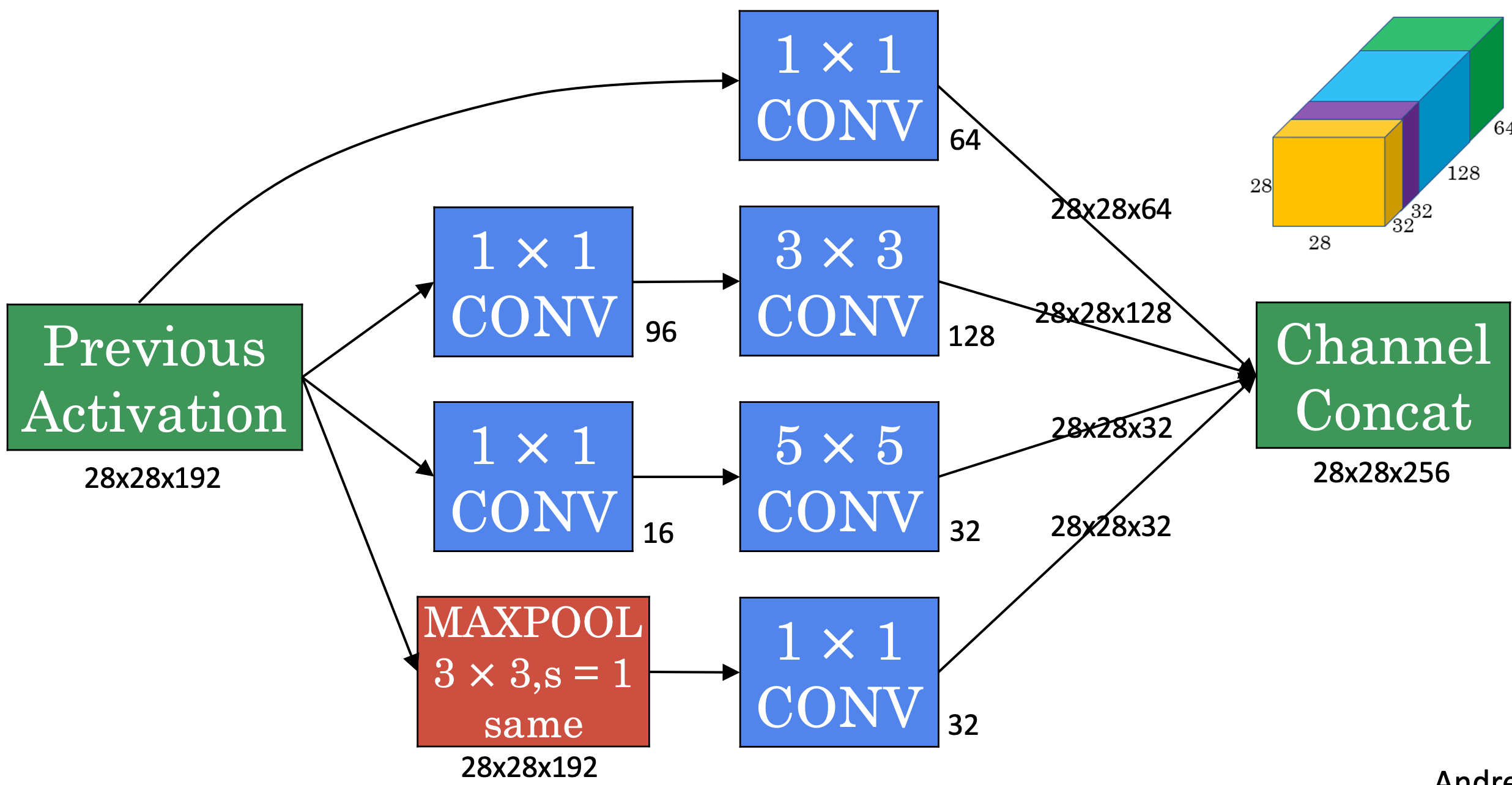
- 위 그림은 (28, 28, 192) 볼륨을 입력으로 받는 Inception Module 이며, 4가지 Layer를 거쳐 나온 결과를 합쳐 출력을 얻습니다.
- 1x1 Conv
- 1x1 Conv -> 3x3 Conv
- 1x1 Conv ->5x5 Conv
- MAXPOOL -> 1x1 Conv
- MAXPOOL layer 뒤에 1x1 Conv layer가 오는 것에 유의해야합니다.
- MAXPOOL은 channel 수를 감소시킬 수 없어서, 1x1 Conv를 통해 channel 수를 줄여줍니다.
- 위 그림은 (28, 28, 192) 볼륨을 입력으로 받는 Inception Module 이며, 4가지 Layer를 거쳐 나온 결과를 합쳐 출력을 얻습니다.
-
즉, Inception Module은 layer에 1x1 Convolution layer를 추가해 bottlenect layer를 구현함으로써, channel 수를 감소시키며, 연산량을 줄이는 구조입니다.
-
이것이 inception module의 기본 아이디어이며, Inception Network는 이러한 Inception Module의 집합입니다.
-
계속해서 어떻게 Full Inception network를 구성할 수 있는지 알아보겠습니다.
Inception(GoogLeNet) Network
-
Inception Network는 Inception Module의 집합이며, Google의 개발자들에 의해서 만들어졌고, GoogLenet이라고도 부릅니다.
-
Inception Network
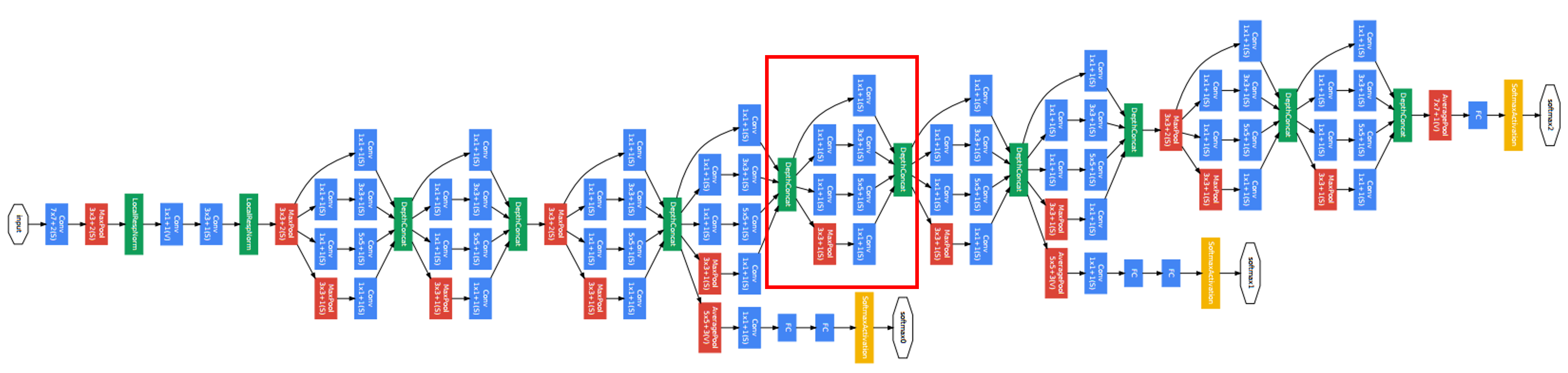
- 모델 초반에는 Inception Module이 들어가지 않습니다.
- Stem 영역이라고 하는데, 모델 초반에는 Inceoption 효과가 크지 않기 때문에 일반적인 Conv-Pool 스타일을 가지고 있습니다.
- 모델 사이에는 Max Pooling이 끼워져 있으며
- 모델의 마지막에는 Fully connected layer로 결과값을 출력하는 구조입니다.
- 중간에 softmax layer가 추가로 달려있는데, 이는 파라미터가 잘 업데이트되도록 도와주며, output의 성능이 나쁘지않게 도와줍니다. 또한 regularization 효과를 얻을 수 있고, overfitting을 방지합니다.
- 모델 초반에는 Inception Module이 들어가지 않습니다.
'AI > Deep Learning' 카테고리의 다른 글
| [DL] Object Localization (객체 위치 식별) (3) | 2021.02.09 |
|---|---|
| [DL] Convolution, Padding, Stride, Pooling in CNN (1) | 2021.02.03 |
| [DL] Transfer Learning(전이학습)이란? (3) | 2021.01.27 |
| [DL] End-to-End Deep Learning 이란? (6) | 2021.01.27 |
| [DL] 배치 정규화(Batch Normalization) (0) | 2021.01.21 |

