
우노
[DL] Convolution, Padding, Stride, Pooling in CNN 본문
- CNN의 Layer 유형은 다음과 같습니다.
- Convolution Layer
- Pooling Layer
- Fully Connected Layer
- 해당 포스트에서는 Convolution Layer와 Pooling Layer 중심으로 다뤄보겠습니다.
Convolution Layer
컨볼루션이란, 원본 이미지에서 특징을 추출하는 수학적 연산을 의미하며
(n, n) 이미지에 (f, f) 크기의 필터를 적용해 특징을 추출하게 됩니다.
아래 그림에서, 녹색 (5, 5) 행렬은 원본 이미지, 노란색 (3, 3) 행렬은 필터입니다.
필터는 원본 이미지 위를 이동하며, 이미지 픽셀 값과 필터 픽셀 값의 내적의 합을 출력으로 나타내게 됩니다.
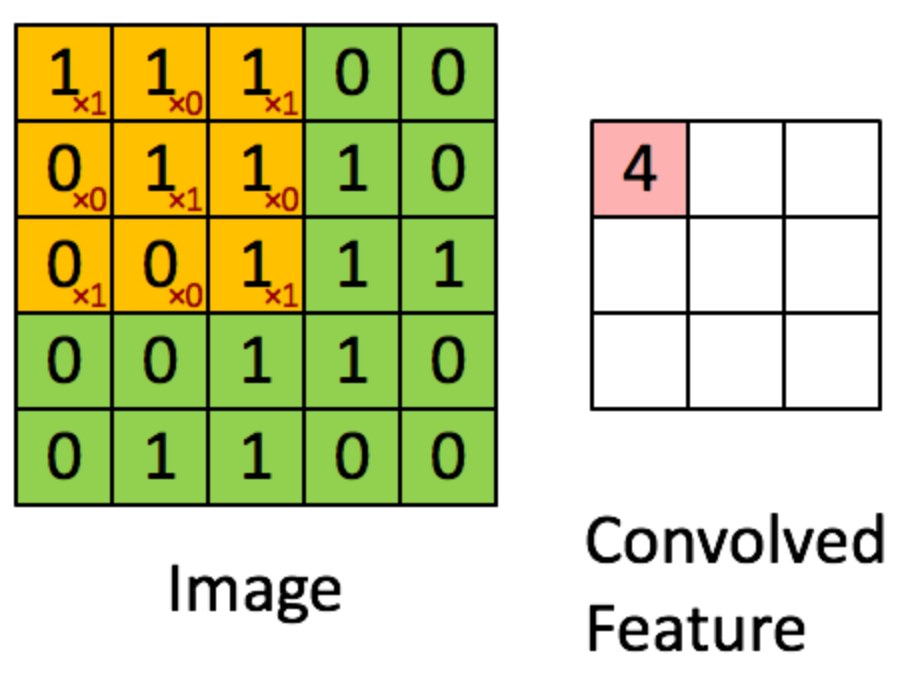
딥러닝에서는, 이미지에서 원하는 특징을 감지할 수 있도록 필터의 값을 학습하게 됩니다.
Filter
필터에는 여러가지 종류가 있습니다.
수직선을 파악하는 vertical filter, 수평선을 파악하는 horizontal filter



열의 중앙에 더 많은 가중치를 부여하는 sobel filter와 scharr filter

따라서, (n, n) 이미지가 (f, f) 필터와 컨볼루션 된 경우, 출력 이미지의 크기는 (n-f+1, n-f+1) 가 됩니다.
하지만, 필터의 단점은 컨볼루션 연산 마다 원본 이미지의 크기가 축소 된다는 것입니다.
Padding
컨볼루션에는 두 가지 문제가 있습니다.
- 첫 번째 문제는, 컨볼루션 연산마다 원본 이미지의 크기가 축소된다는 것입니다.
- 우리는 이미지가 매번 축소되는 것을 원하지 않습니다.
- 두 번째 문제는, 필터가 원본 이미지 위를 이동할 때, 이미지의 모서리에 있는 픽셀은 한 번 만 사용되는 반면에 이미지의 가운데 있는 픽셀은 여러번 사용된다는 것입니다.
- 즉, 이미지의 모서리에 있는 정보는 약해지며, 이미지의 가운데에 있는 정보는 과해지는 것입니다.
- 첫 번째 문제는, 컨볼루션 연산마다 원본 이미지의 크기가 축소된다는 것입니다.
따라서, 이 두 가지 문제를 해결하기 위해 Padding 이라는 새로운 개념이 도입되었습니다.
패딩은 원본 이미지에 추가적인 경계선을 덧댐으로써, 원본 이미지의 크기를 유지합니다.
(n, n) 이미지에 대해 p 만큼 패딩한 후 (f, f) 필터로 컨볼루션 한 출력 이미지의 크기는 (n+2p-f+1, n+2p-f+1)이 됩니다.
아래 그림은, (3, 3) 이미지에 대해 1 만큼 패딩한 후 (2, 2) 필터로 컨볼루션 한 예제이며
출력 이미지의 크기는 (4, 4)가 됩니다.
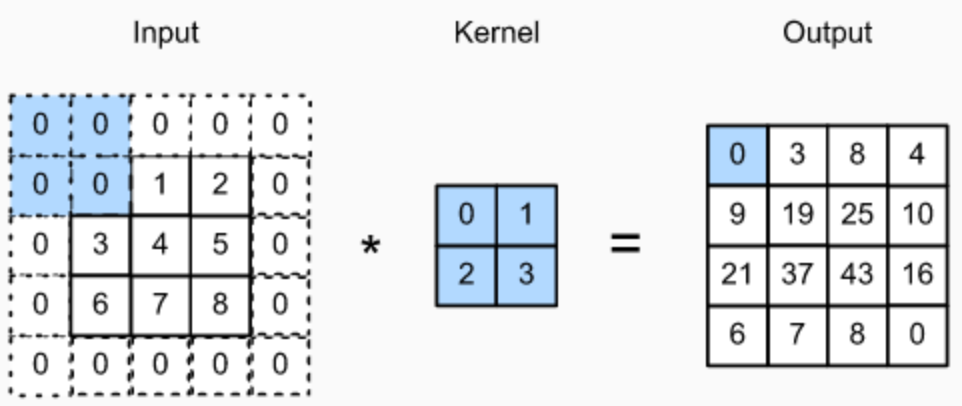
convolution은 원본 이미지에 패딩을 얼마다 덧대느냐에 따라 Valid convolution, Same convolution로 나뉘어집니다.
- Valid convolution : 패딩 없이, 원본 이미지 크기가 축소되는 것
- (n, n) * (f, f) = (n-f+1, n-f+1)
- Same convolution : 패딩을 사용해, 원본 이미지와 출력 이미지의 크기가 동일해지는 것
- (n, n) * (f, f) = (n+2p-f+1, n+2p-f+1) = (n, n)
- Valid convolution : 패딩 없이, 원본 이미지 크기가 축소되는 것
Stride

- Stride는 입력 이미지에서 필터를 몇 칸 씩 건너띄며 적용할지를 의미합니다.
- Stride가 1이라면, 한 칸씩 건너띄며 필터를 적용하고
- Stride가 2라면, 두 칸씩 건너띄며 필터를 적용합니다.
- (n, n) 이미지에 대해 p 만큼 패딩한 후 (f, f) 필터로 s 만큼 스트라이드하며 컨볼루션 한다면
- 출력 이미지의 크기는 ((n+2p-f)/s+1, (n+2p-f)/s+1)이 됩니다.
- (N+2p-f)/s + 1 가 실수라면 소수점 아래 부분은 버립니다.
Pooling Layer
CNN에는 Convolution layer 외에도 Pooling layer가 존재합니다.
Convolution layer와 Pooling layer 모두 필터를 사용하지만
풀링은 네트워크의 복잡성과 계산 비용을 줄일 수 있습니다.
풀링에는 두 가지 유형이 있습니다.
- Max Pooling
- Average Pooling
Max Pooling
Max Pooling은 입력 이미지를 필터 크기만큼의 여러 영역으로 나눈 다음,
이미지 위에서 필터를 이동하며, 필터 영역 내에서 최대값을 뽑으며 진행됩니다.
Max Pooling은 이미지에서 중요한 정보를 잡아놓는데 도움이 됩니다.
아래 그림은, (4, 4) 이미지에 대해 (2, 2) 필터로 2만큼 stride 하며 Max Pooling 한 것입니다.

Average Pooling
Average Pooling은 입력 이미지를 필터 크기만큼의 여러 영역으로 나눈 다음,
이미지 위에서 필터를 이동하며, 필터 영역 내에서 평균값을 뽑으며 진행됩니다.
Average Pooling은 이미지에서 중요한 정보와 덜 중요한 정보를 균형있게 잡아놓는데 도움이 됩니다.
아래 그림은, (4, 4) 이미지에 대해 (2, 2) 필터로 2만큼 stride 하며 Average Pooling 한 것입니다.

Pooling Layer의 흥미로운 특징 중 하나는, Convolution layer는 특징을 뽑아내는 적합한 filter를 학습하는 반면에, Pooling Layer는 학습하는 파라미터가 없다는 것입니다.
- Pooling layer에서 f, s 는 모두 하이퍼파라미터로 주어집니다.
따라서, Pooling은 보통 원본 이미지의 정보를 유지하며 크기를 줄이는 용도로 사용됩니다.
- Pooling에서 Padding은 잘 사용되지 않습니다.
입력 이미지 크기로부터 출력 이미지 크기를 추론하는 공식은 Convolution layer와 Pooling layer 모두 동일합니다.
- (n, n) 이미지에 대해 p 만큼 패딩한 후 (f, f) 필터로 s 만큼 스트라이드하며 풀링 한다면,
- 출력 이미지의 크기는 ((n+2p-f)/s+1, (n+2p-f)/s+1)이 됩니다.
- (N+2p-f)/s + 1 가 실수라면 소수점 아래 부분은 버립니다.
- 위 그림에서는, n = 4, p = 0, f = 2, s = 2 이므로 출력 이미지의 크기는 (2, 2)가 됩니다.
3D Convolution Layer
지금까지 2D image에 대한 convolution을 다뤄보았습니다.
이제 2D image가 아닌 3D rgb image 에 대한 convolution을 다뤄보겠습니다.
우선, 3D 구조는 (height, width, channel)로 표현되며
아래 그림은, (6, 6, 3) 입력 이미지에 (3, 3, 3) 필터 블록을 하나만 적용한 결과입니다.

- 입력 이미지의 channel 수와 필터 블록의 channel 수는 동일해야하며
- 필터 블록 당, 1개의 channel을 가진 이미지가 출력됩니다.
- 또한, 출력 이미지는 1개의 bias 값이 더해진 뒤, 비선형 함수가 적용됩니다.
만약, 필터 블록을 하나가 아닌 두 개를 적용한다면 결과는 아래 그림과 같습니다.

- 이 경우에도, 입력 이미지의 channel 수와 필터 블록의 channel 수는 동일해야하며
- 필터 블록 당, 1개의 channel을 가진 이미지가 출력됩니다.
- 출력 이미지는 1개의 bias 값이 더해진 뒤, 비선형 함수가 적용됩니다.
- 필터 블록은 총 2개 사용되었기 때문에, 최종 출력 이미지는 2개의 channel을 가지게 됩니다.
따라서, (n, n, c) 이미지에 대해 p 만큼 패딩한 후, c' 개의 (f, f, c) 필터 블록으로 s 씩 건너띄며 컨볼루션 한다면,
출력 이미지의 크기는 ((n+2p-f)/s+1, (n+2p-f)/s+1, c') 가 됩니다.
그렇다면, (6, 6, 3) 이미지에 (3, 3, 3) 필터 블록 10개를 적용한다면, 해당 convolution layer는 몇 개의 파라미터를 가지고 있을까요?
- 각 필터 블록은 3 x 3 x 3 = 27개의 파라미터를 가지며
- 출력 이미지 당 1개의 bias를 가지고 있습니다.
- 따라서, 파라미터는 필터 블록당 28개이며
- 총 10개의 필터 블록을 사용하기 때문에 280개의 파라미터를 가지고 있는 것과 동일합니다.
CNN Example
'AI > Deep Learning' 카테고리의 다른 글
| [DL] Landmark Detecting (1) | 2021.02.09 |
|---|---|
| [DL] Object Localization (객체 위치 식별) (3) | 2021.02.09 |
| [DL] LeNet-5, AlexNet, VGG-16, ResNet, Inception Network (1) | 2021.02.03 |
| [DL] Transfer Learning(전이학습)이란? (3) | 2021.01.27 |
| [DL] End-to-End Deep Learning 이란? (6) | 2021.01.27 |


